Rows: 13,583
Columns: 13
$ age <int> 14, 14, 15, 15, 15, 15, 15, 14, 15, 15, 15, 1…
$ gender <chr> "female", "female", "female", "female", "fema…
$ grade <chr> "9", "9", "9", "9", "9", "9", "9", "9", "9", …
$ hispanic <chr> "not", "not", "hispanic", "not", "not", "not"…
$ race <chr> "Black or African American", "Black or Africa…
$ height <dbl> NA, NA, 1.73, 1.60, 1.50, 1.57, 1.65, 1.88, 1…
$ weight <dbl> NA, NA, 84.37, 55.79, 46.72, 67.13, 131.54, 7…
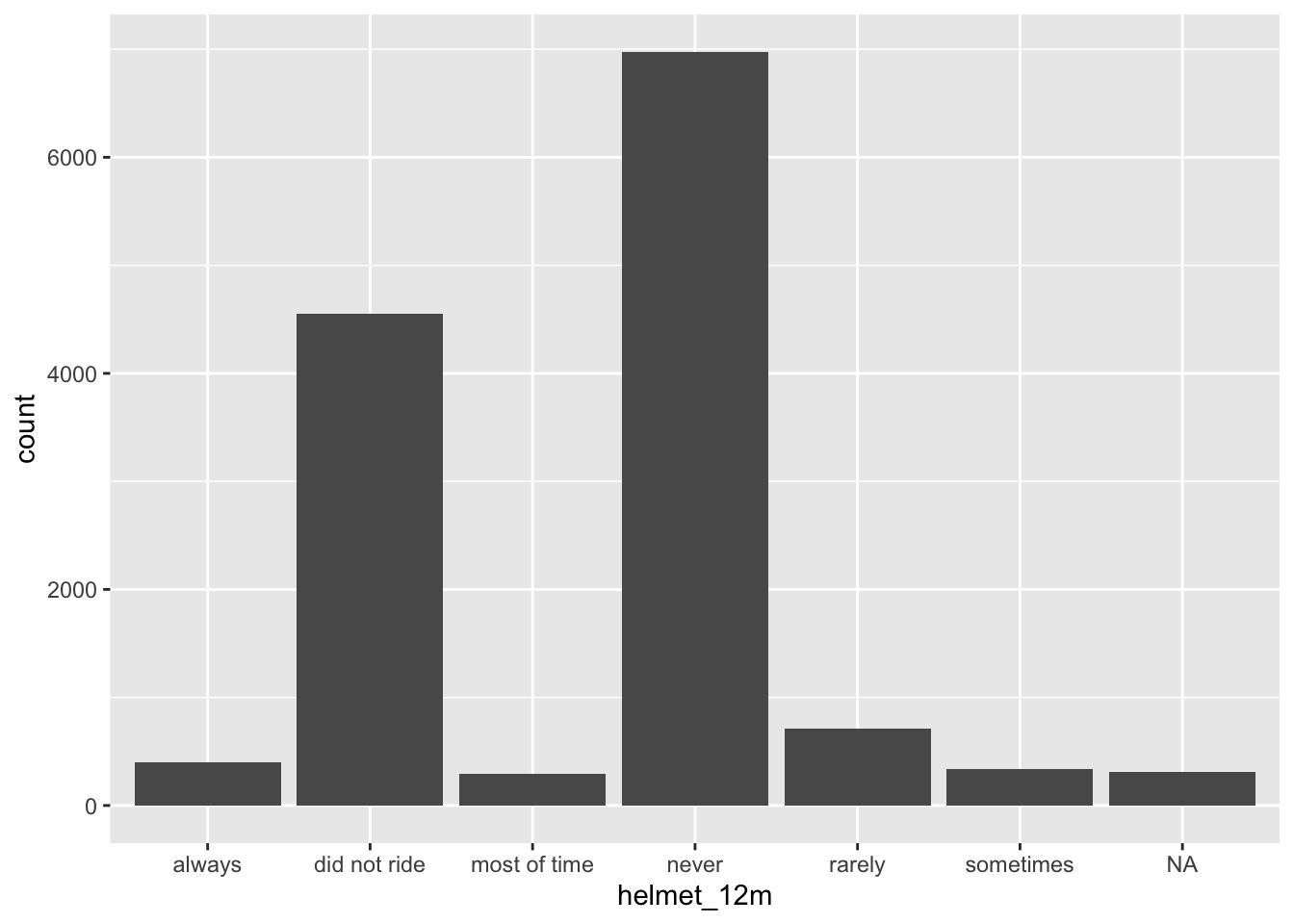
$ helmet_12m <chr> "never", "never", "never", "never", "did not …
$ text_while_driving_30d <chr> "0", NA, "30", "0", "did not drive", "did not…
$ physically_active_7d <int> 4, 2, 7, 0, 2, 1, 4, 4, 5, 0, 0, 0, 4, 7, 7, …
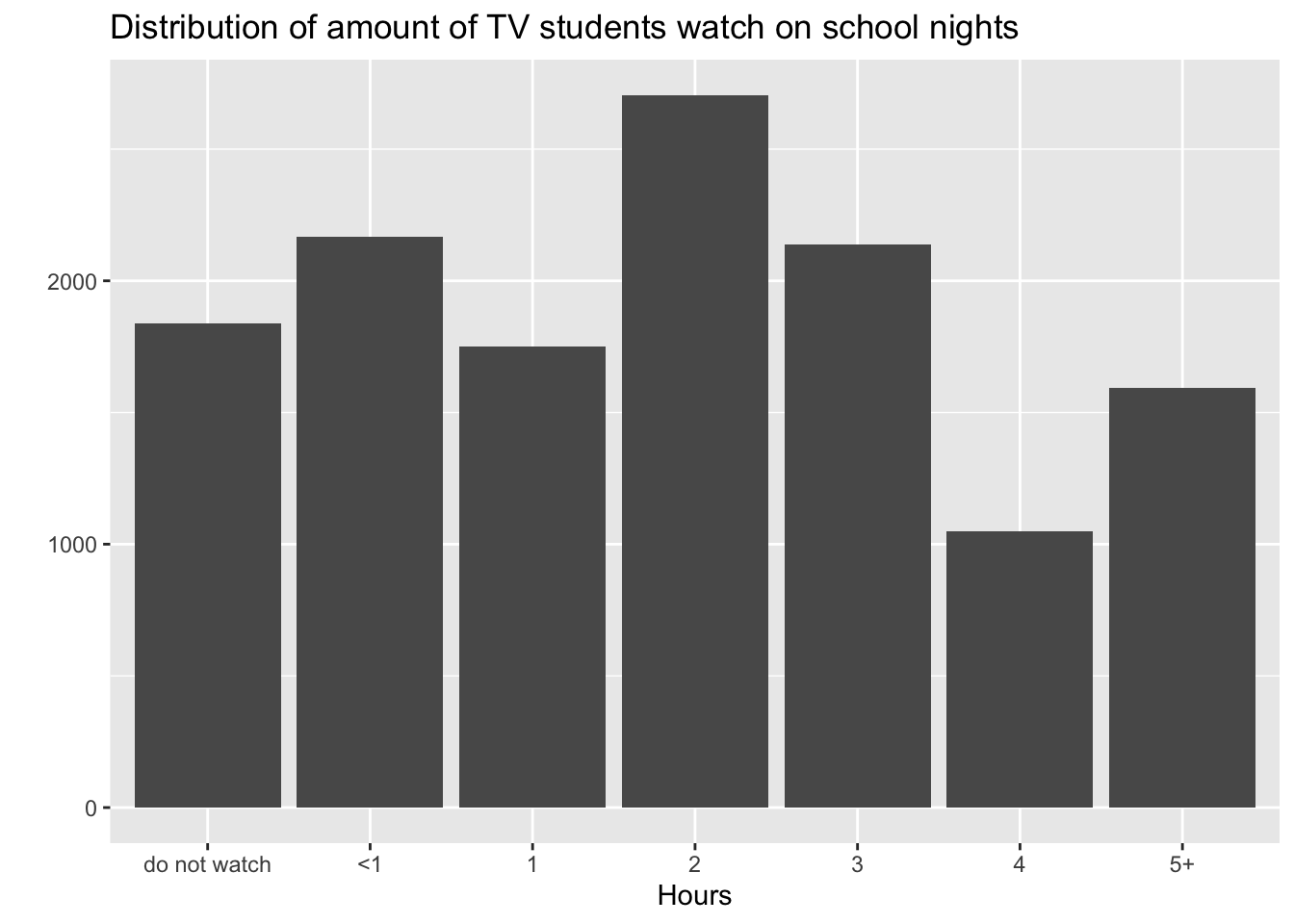
$ hours_tv_per_school_day <chr> "5+", "5+", "5+", "2", "3", "5+", "5+", "5+",…
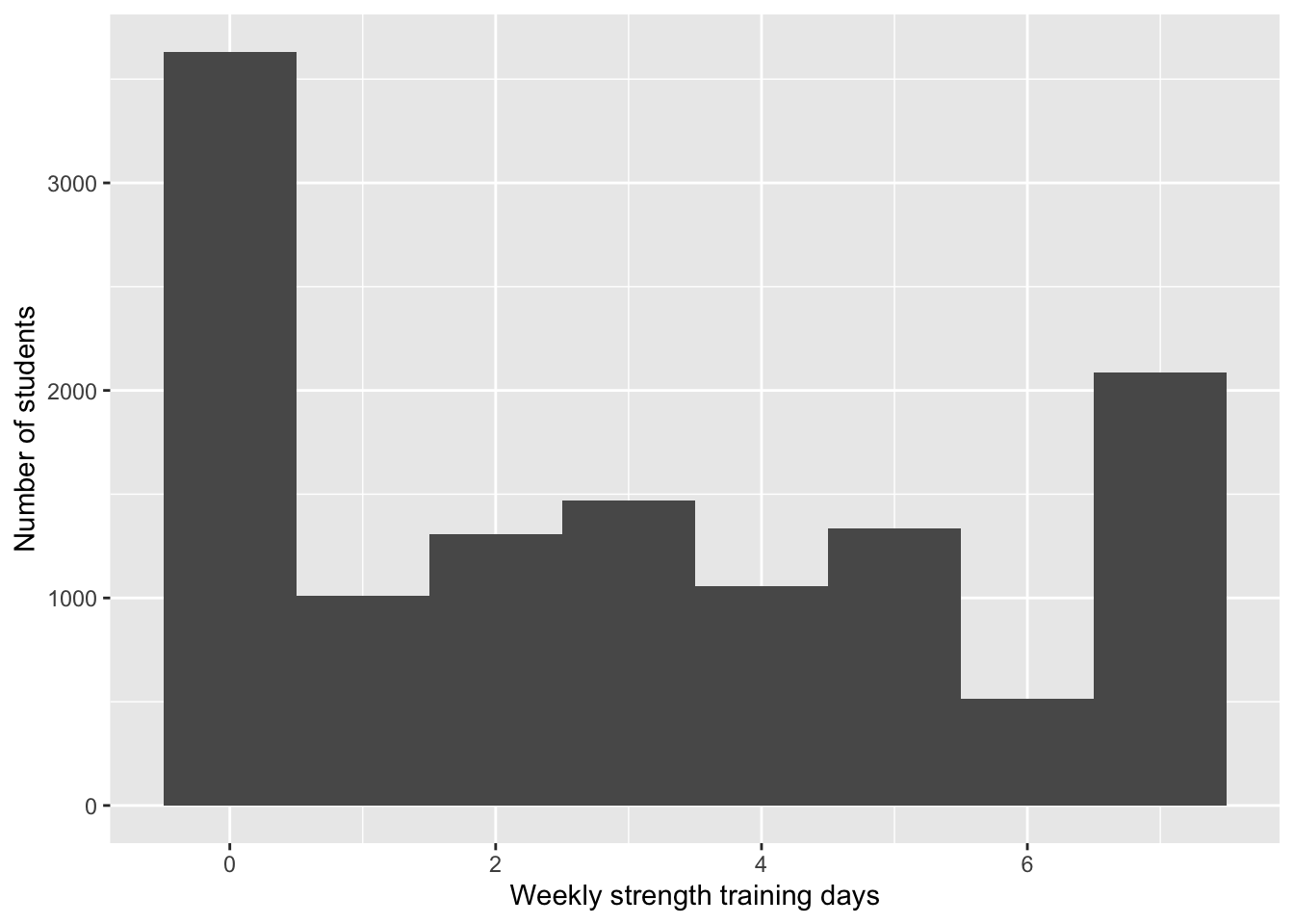
$ strength_training_7d <int> 0, 0, 0, 0, 1, 0, 2, 0, 3, 0, 3, 0, 0, 7, 7, …
$ school_night_hours_sleep <chr> "8", "6", "<5", "6", "9", "8", "9", "6", "<5"…