Hypothesis tests pt 2
Lecture 14
2023-06-12
General hypothesis test logic
- Would the sample fall within the distribution of the samples you would get under the null hypothesis (the null distribution)?
Z scores
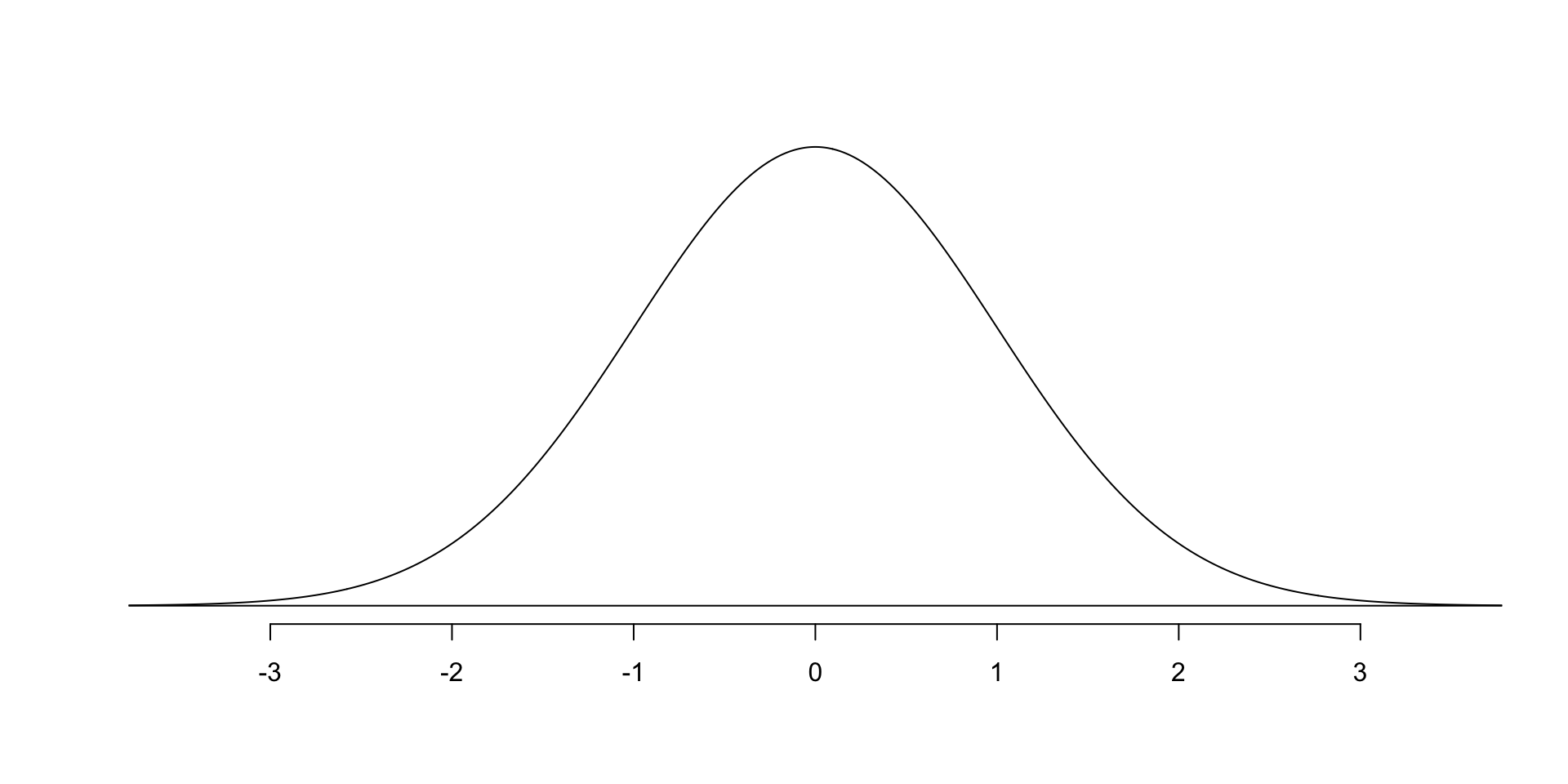
Z scores are a measure of how far an observation is from the center of a normal distribution, in units of standard deviation (or standard error–more on the difference in a moment).
Z scores are the test statistic for the normal distribution
Why are standard units important? For comparing across distributions.
- A Z score of -1 means the same thing in every normal distribution: the observation is one standard deviation below the mean.
Standard deviation vs standard error
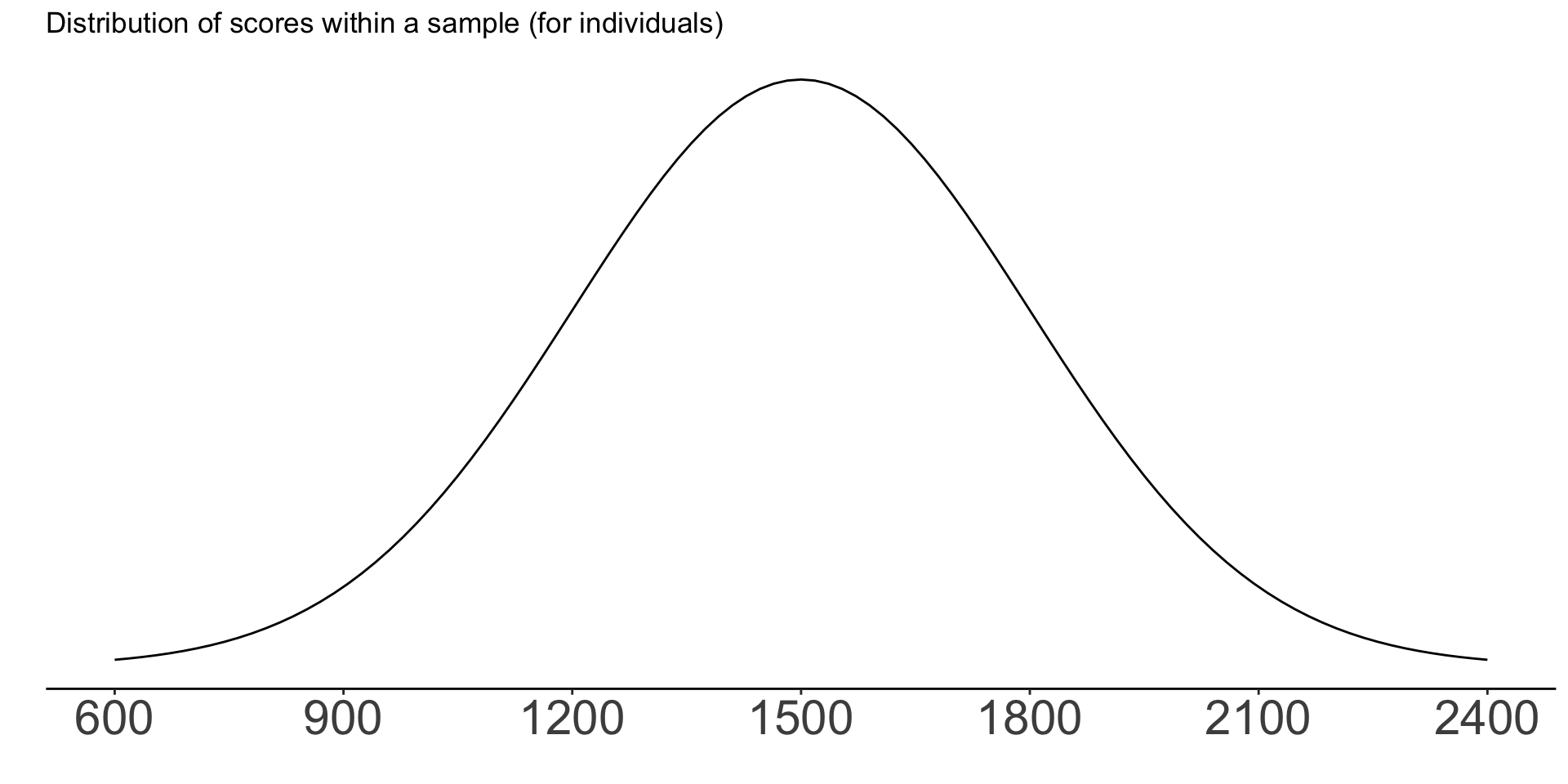
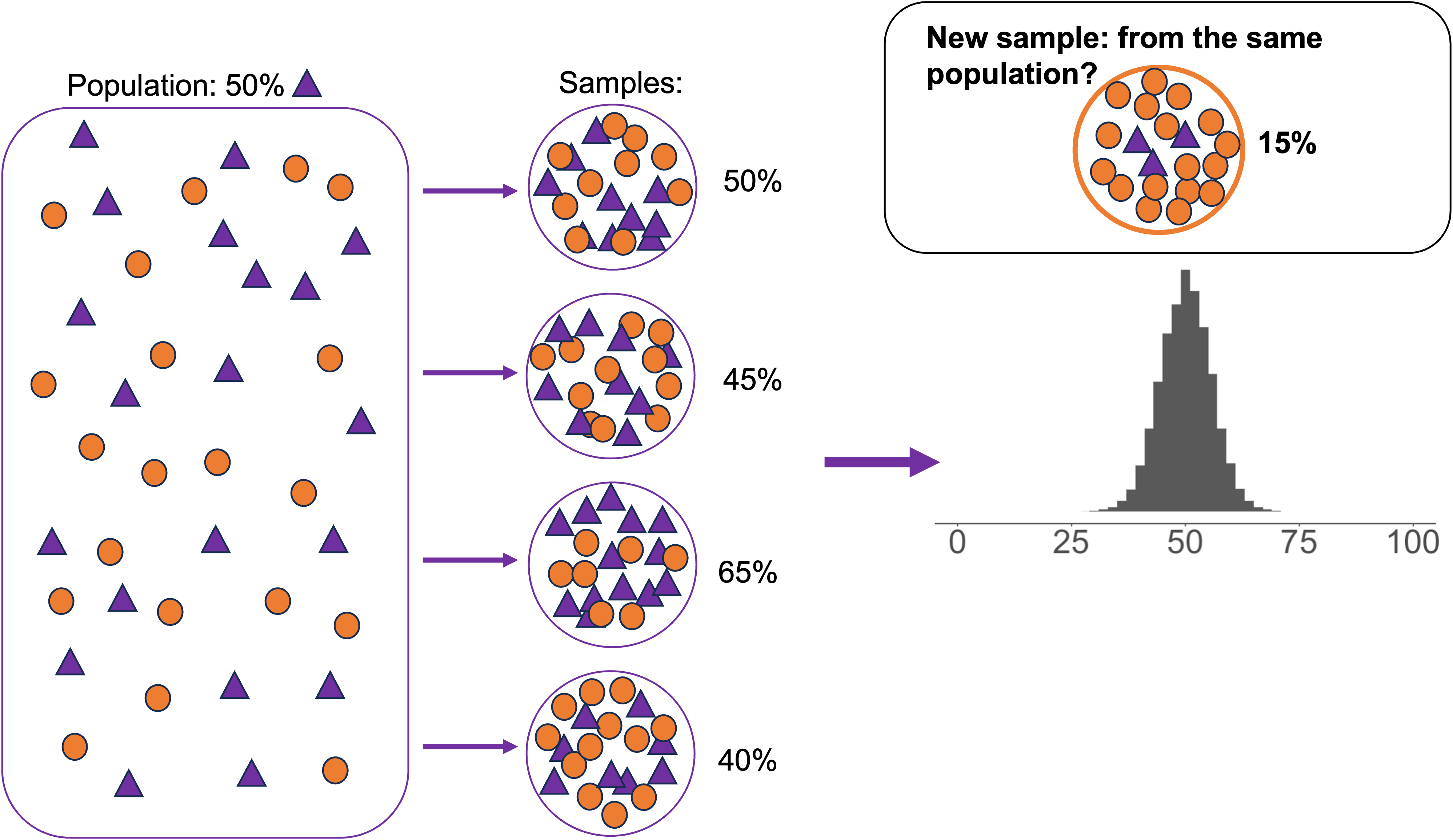
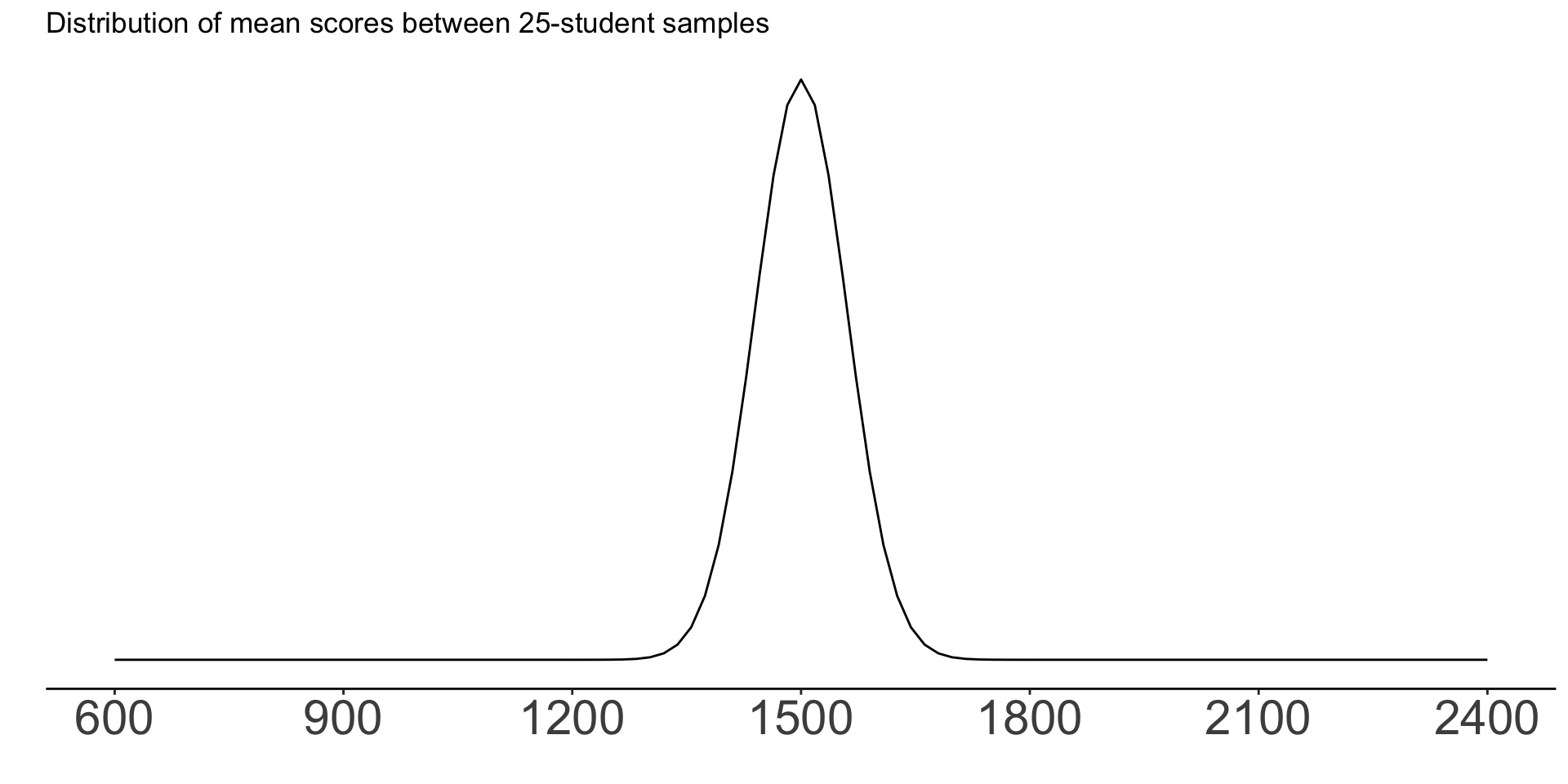
Now imagine that we randomly sampled students and asked them to provide their SAT scores. We have many samples of 25 students each.
The mean score in each 25-student sample is our sample statistic
The term for the spread of this sampling distribution is the standard error.
It is determined by formulas that vary depending on the specific situation. You generally won’t calculate it yourself; it will be provided in R output.
Standard error is always smaller than standard deviation: there is more variation within samples from the same population than between them.
Percentiles
Percentile: What percent of the data is below a particular observation.
From 0% to 100%, but generally reported as a proportion instead (0-1).
Something that can be calculated with software (like R)
- The
pnorm()function takes a Z score and gives you the corresponding percentile
- The
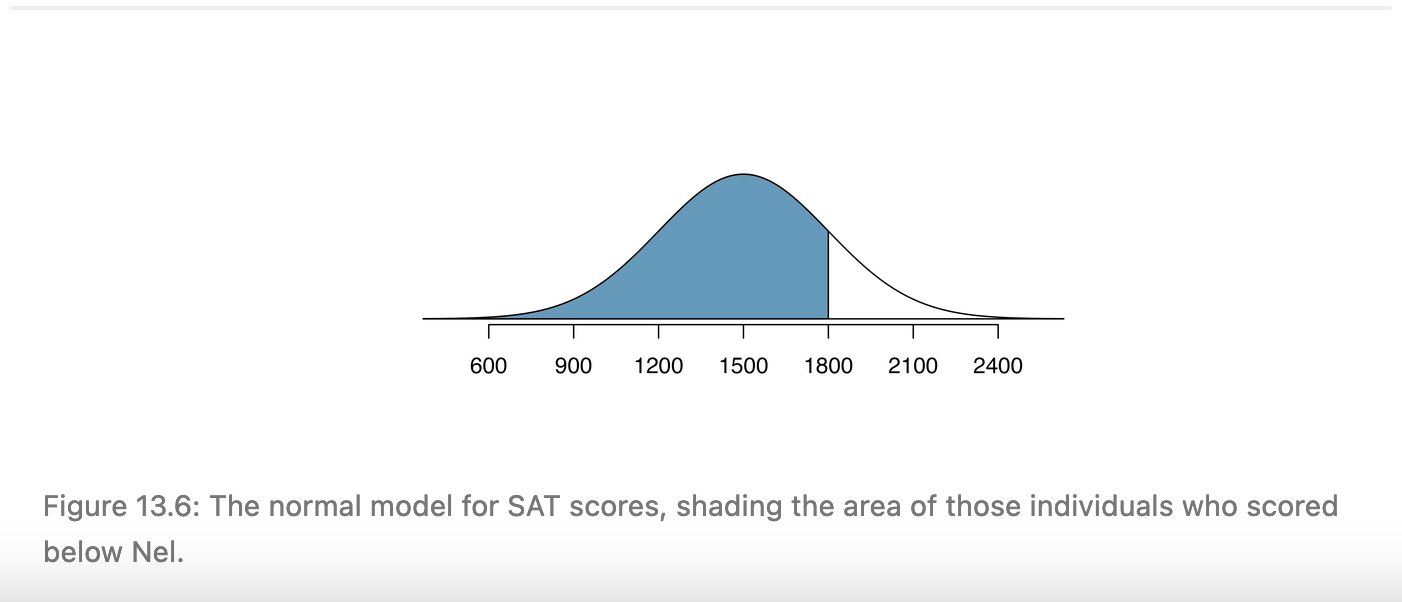
Z scores and percentiles
- 68% of observations are within 1 standard error/standard deviation of the mean
- 95% are within 2 standard errors/standard deviations
- 99.7% are within 3 standard errors/standard deviations
Z scores, percentiles, and p values: example
- Heights of US adults who identify as men follow a normal distribution. Mean = 70 inches; standard deviation = 3.3 inches.
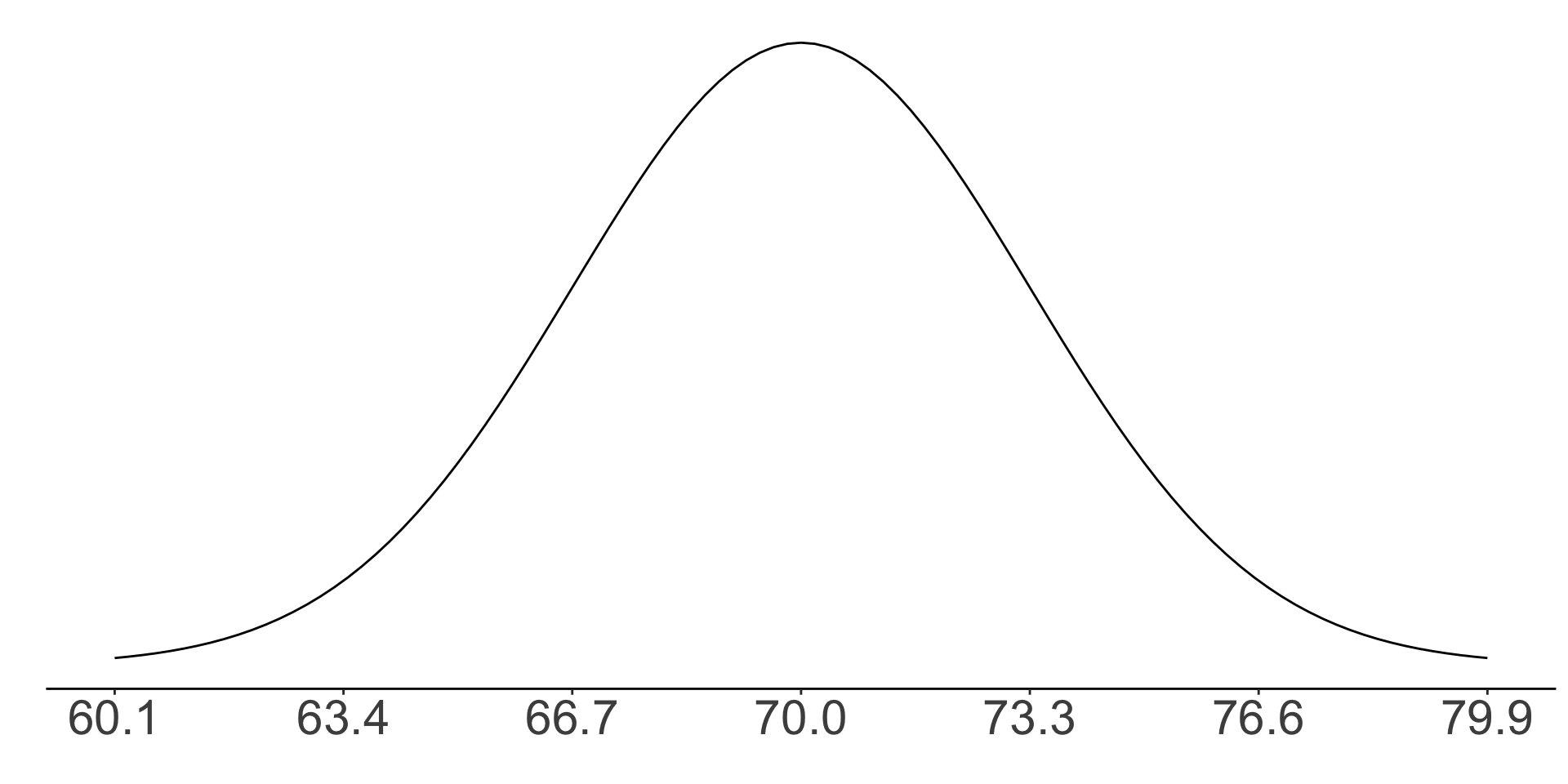
Z scores: exercise Q1
What is the Z score of a man who is 70 inches tall?
- Zero!
- 70 is the mean of this distribution. An observation whose value is exactly equal to the mean has a Z score of 0.
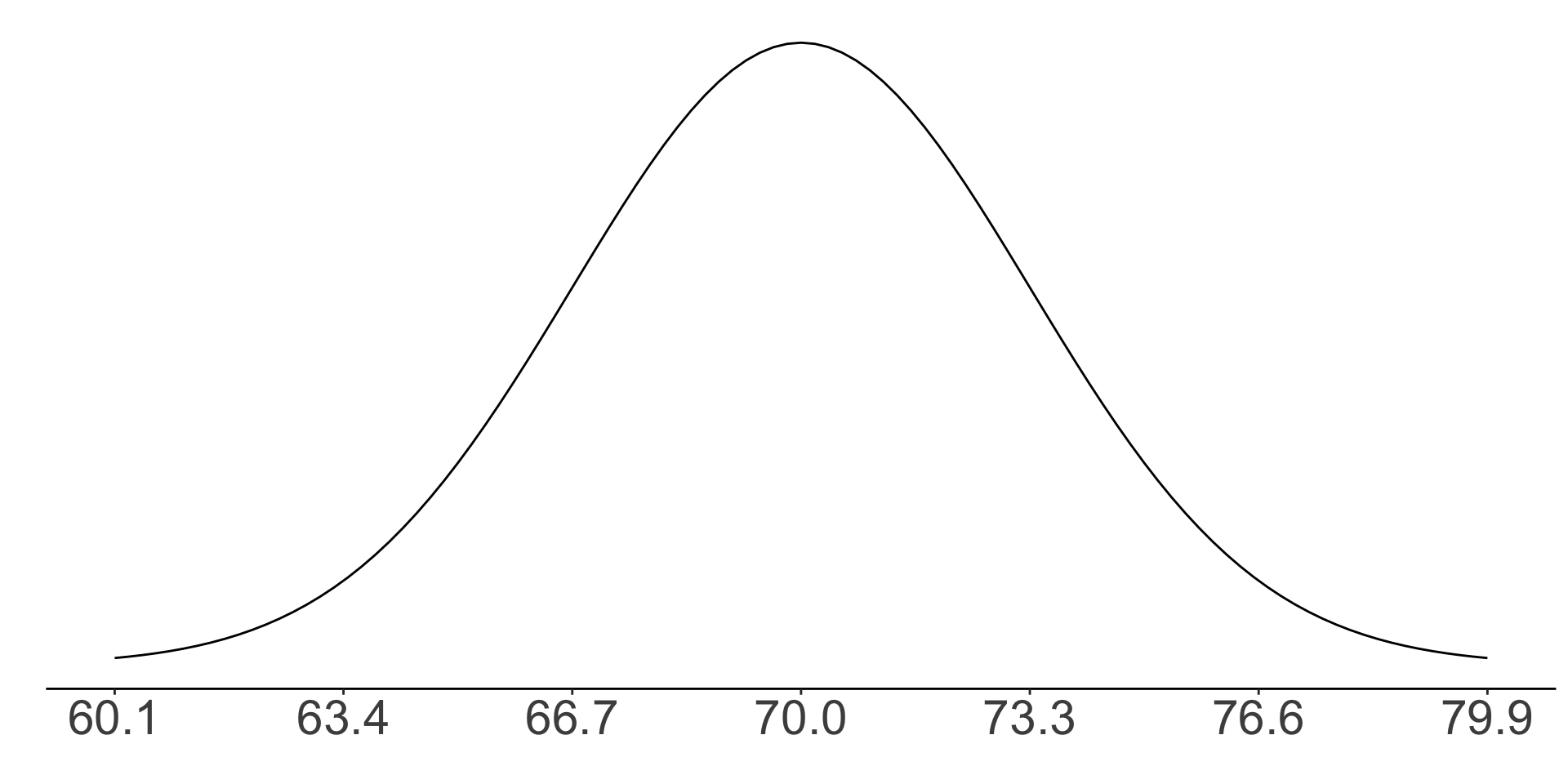
Z scores: exercise Q2
What is the Z score of a man who is 65 inches tall?
- About 1.3
- About -3
- About -1.5
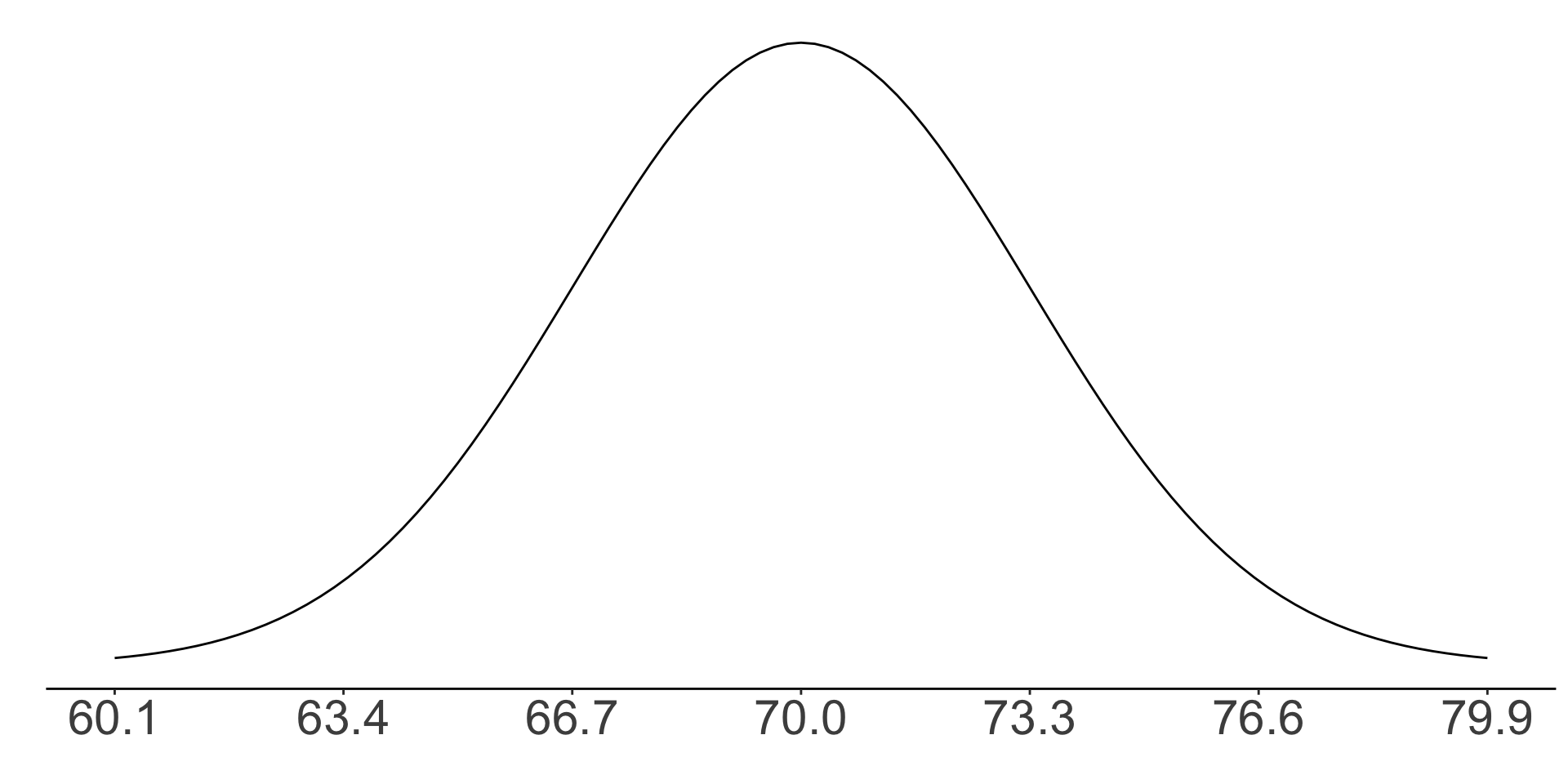
Z scores: exercise Q2
- About -1.5
Percentiles: exercise Q3
If someone is in the 30th percentile in terms of height, is their height most likely:
- About 68 inches
- About 72 inches
- About 62 inches
Percentiles: exercise Q3
- About 68 inches
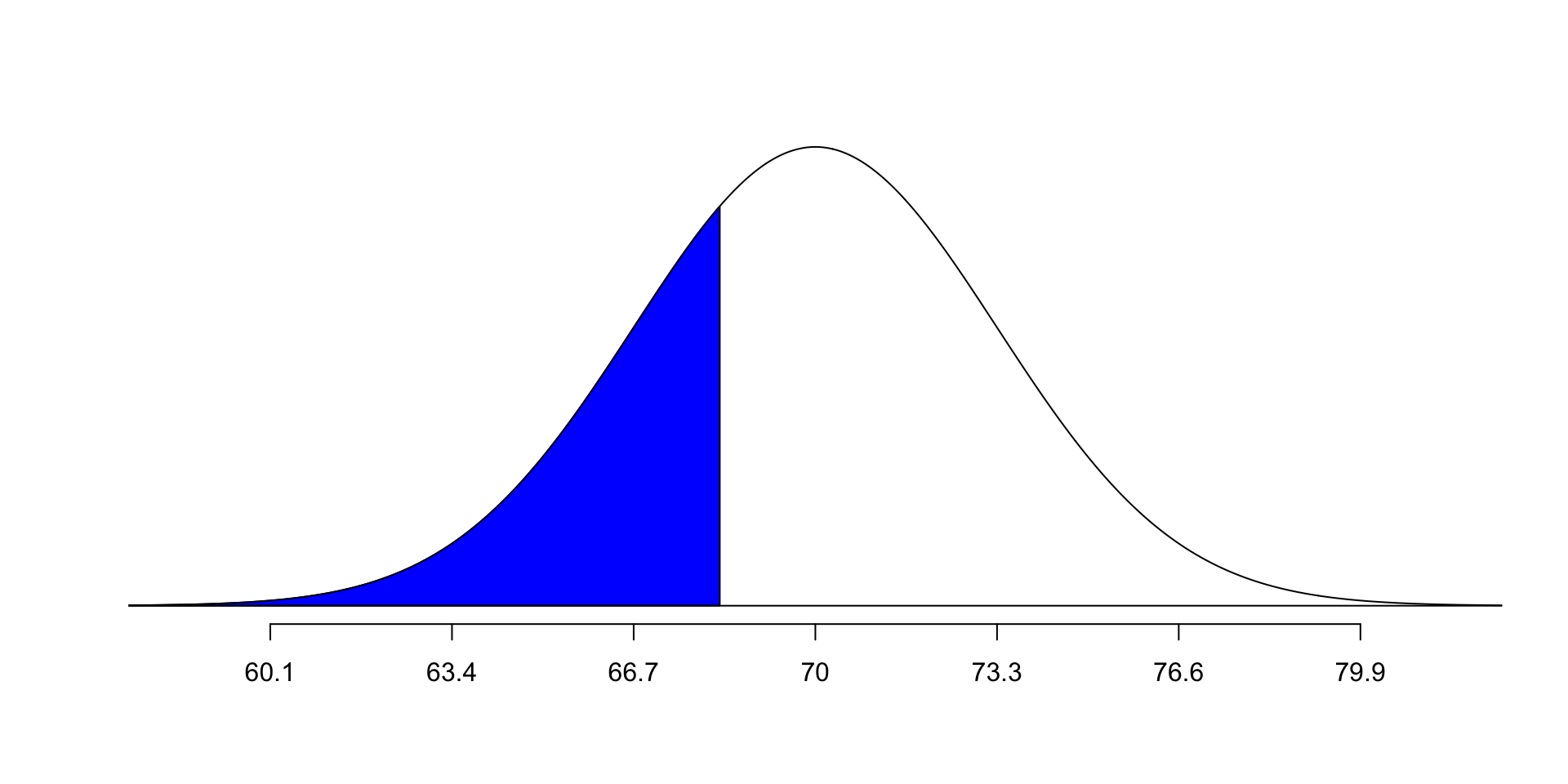
One-tailed p values
The p value for a one-tailed test is the percent of the distribution that is either bigger or smaller than the observed value (depending on which direction the hypothesis takes).
Example: If you randomly select an American who identifies as a man, what is the probability his height will be 63.4 inches or less? (recall the height distribution: mean 70 inches, standard deviation 3.3 inches)
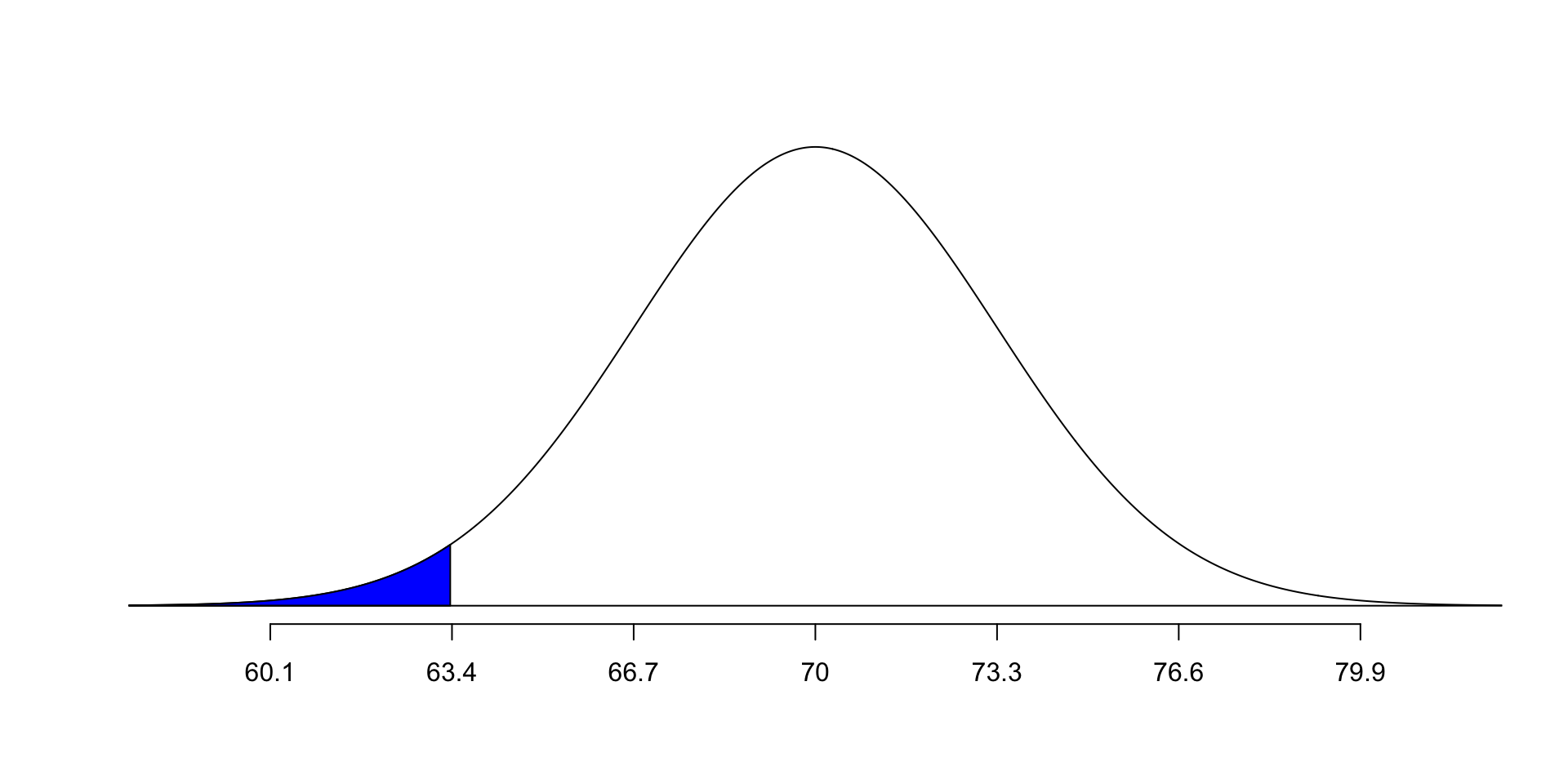
One-tailed p values
What is the probability of randomly selecting an American man who is 76.6 inches tall or taller? (use the same height distribution)
First: Draw the distribution and shade the area we are interested in.
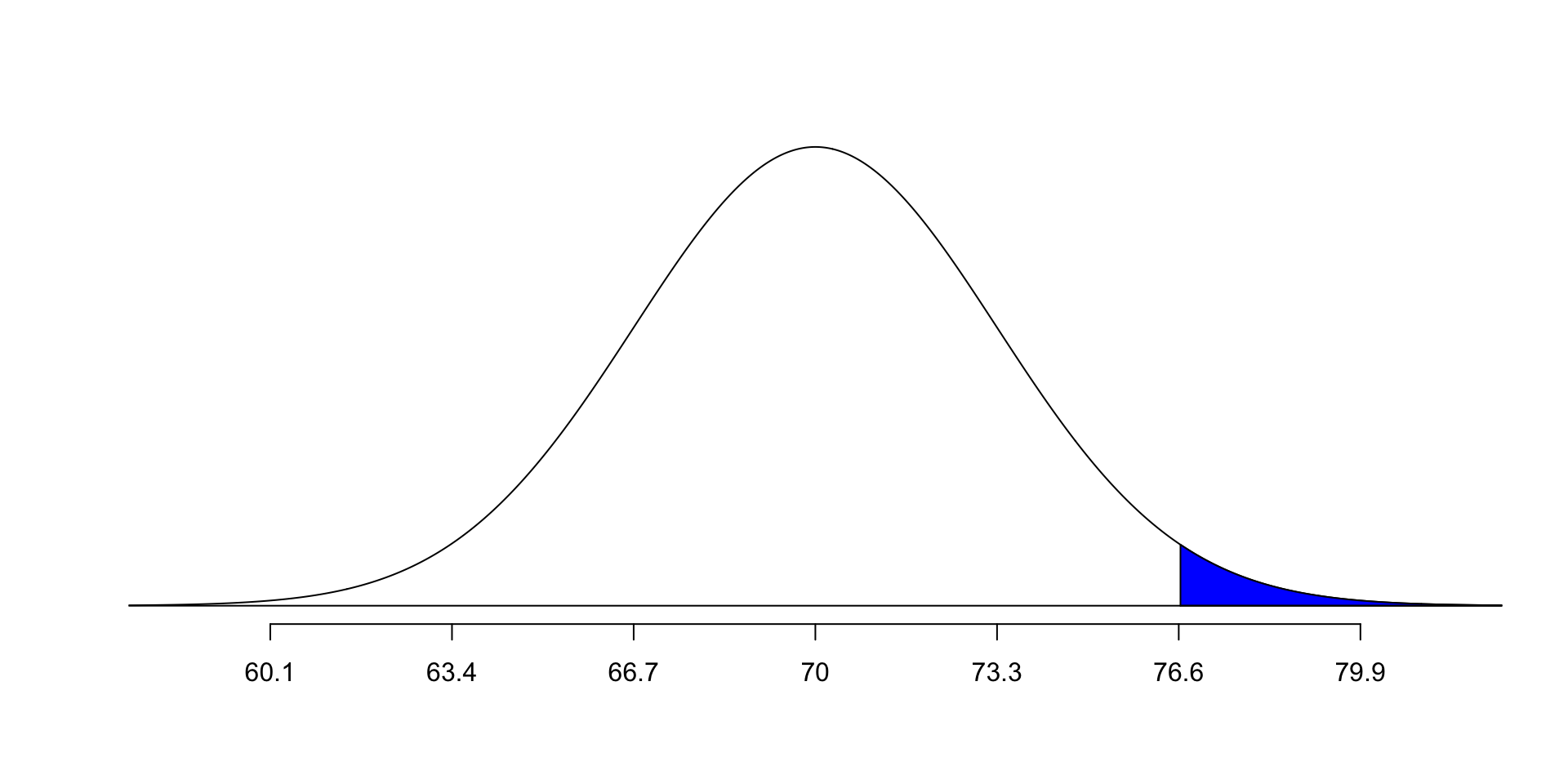
One tailed p values
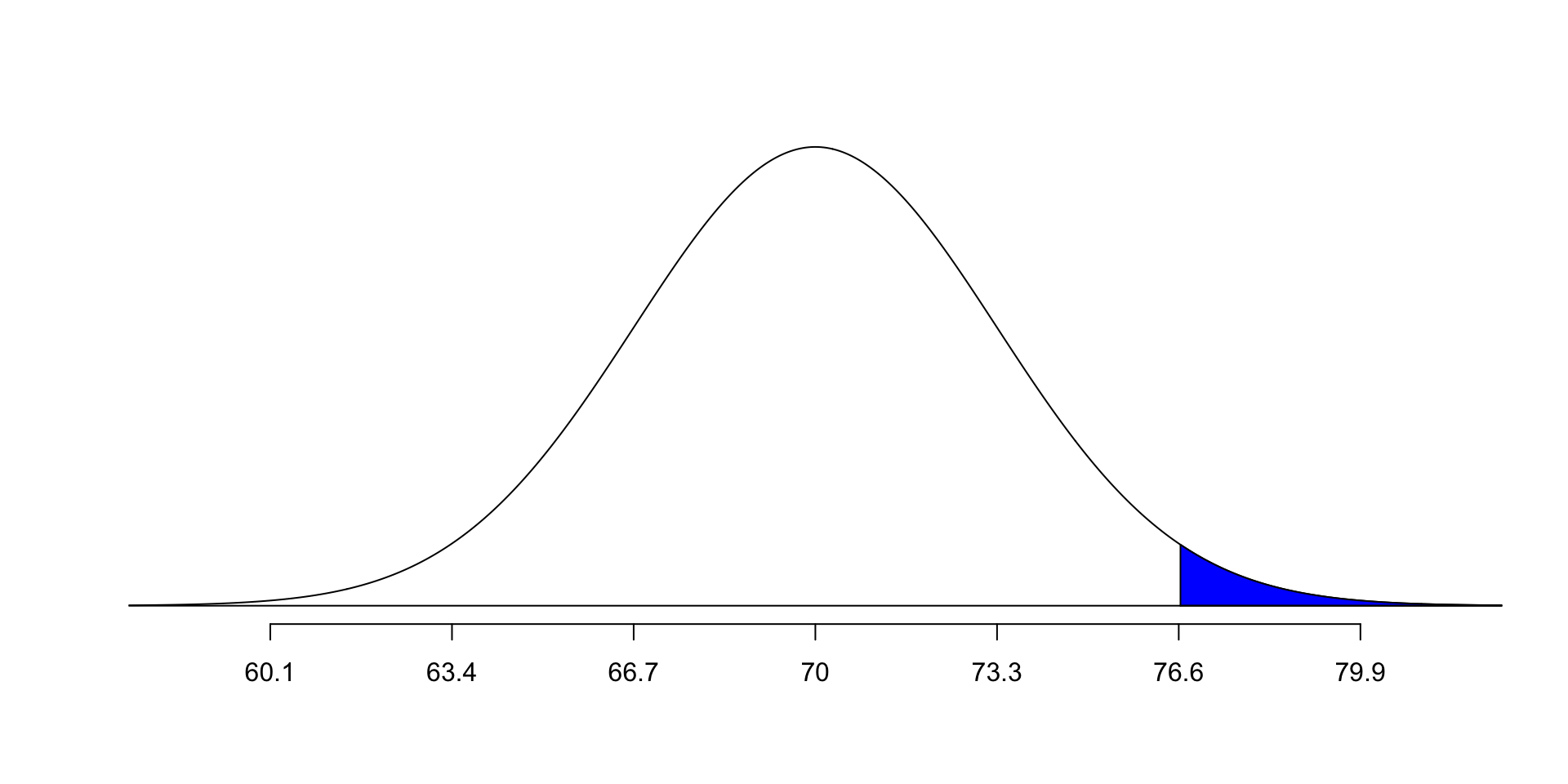
- What is the p value here?
- Is it the same as the percentile?
Two-tailed p values
Example: What is the probability of randomly selecting an American man whose height is two or more standard deviations from the mean?
- In other words: the probability of randomly selecting a man who is either 63.4 inches or shorter OR 76.6 inches or taller
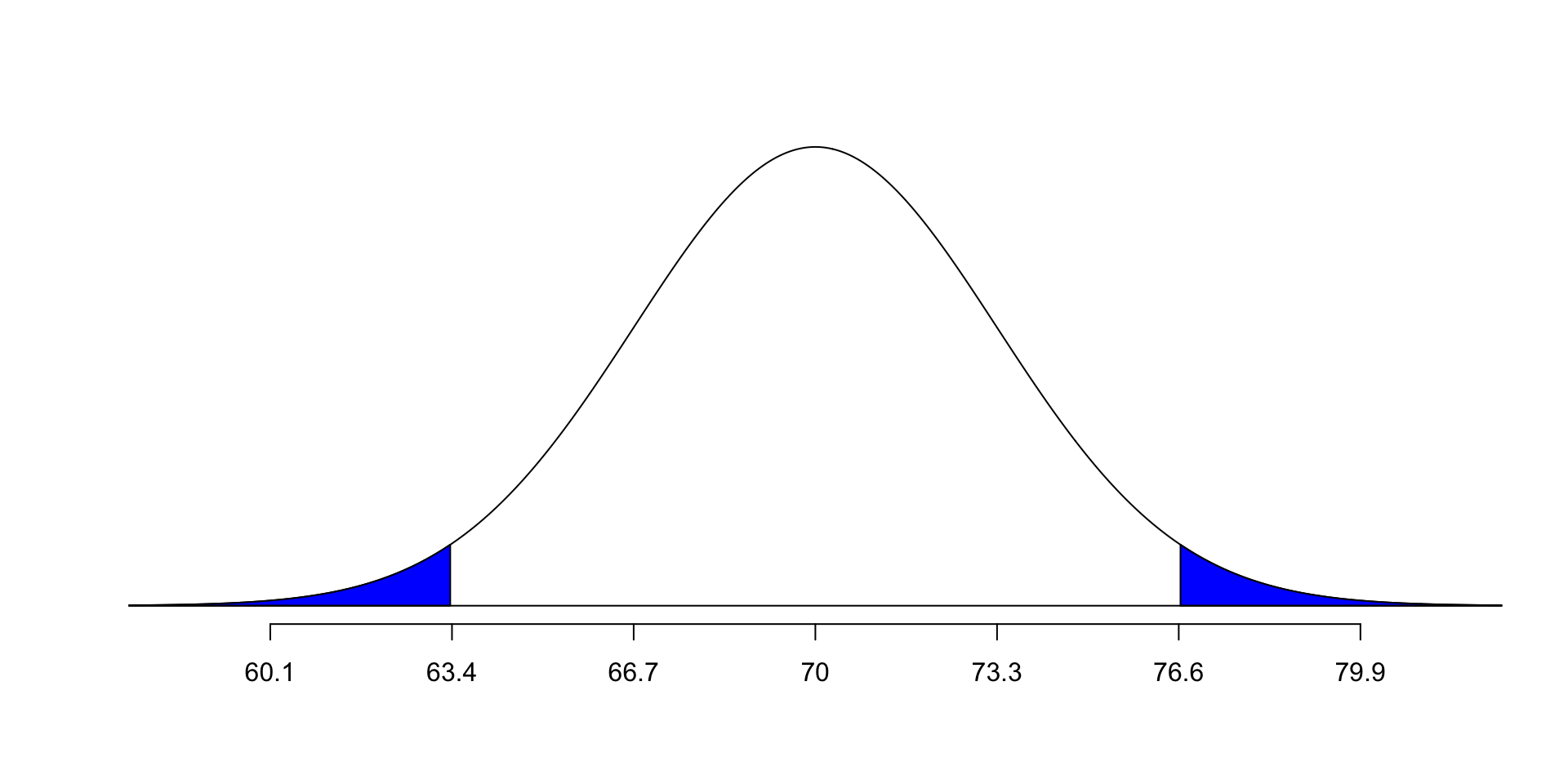
Different types of tests: An overview
- Which test to use is not as cut-and-dry as you might hope—there is overlap in use cases. This is my recommendation for this class.
- These terms won’t mean much to you right now. We’ll come back to the specifics.

Identifying the right test: exercise Q4
For each of these research questions, identify the explanatory variable, the response variable, their types, and the correct statistical test. Think about what the data would look like for each individual in these cases
- How does whether a student attended a public or private school affect their chances of graduating high school?
- How do outcomes of traffic stops (warnings, citations, or arrests) vary by the race of the driver?
- How does the probability a doctor refers a patient to a specialist vary by the patient’s body mass index?
- How is a country’s average life expectancy related to the amount of money per person it spends on health care?
Running a hypothesis test in R with infer
The bad news: there are a lot of different tests.
The good news: regardless of what specific test you run, the logic is similar, and your code will look about the same!
We will be using the
inferpackage to conduct hypothesis testsinferis built to work on similar logic to the tidyverse—wherefilter(),mutate(), andggplot()are from- Its documentation is excellent—check out the website (link here) if you ever get stuck