[1] 2.949948Hypothesis tests pt 1
Lecture 13
2023-06-08
The (approximate) data analysis process
- Determine topic ✓
- Find data; learn what observations and variables are available ✓
- Write research question ✓
- Describe distributions of relevant variables ✓
- Prepare data frame for analysis ✓
- Describe relationships between variables ✓
- Perform statistical tests/write models
- Communicate results

Hypotheses: exercise q1

Hypotheses: exercise q2
- Write the null and alternative hypotheses for the following studies:

Population parameters and sample statistics
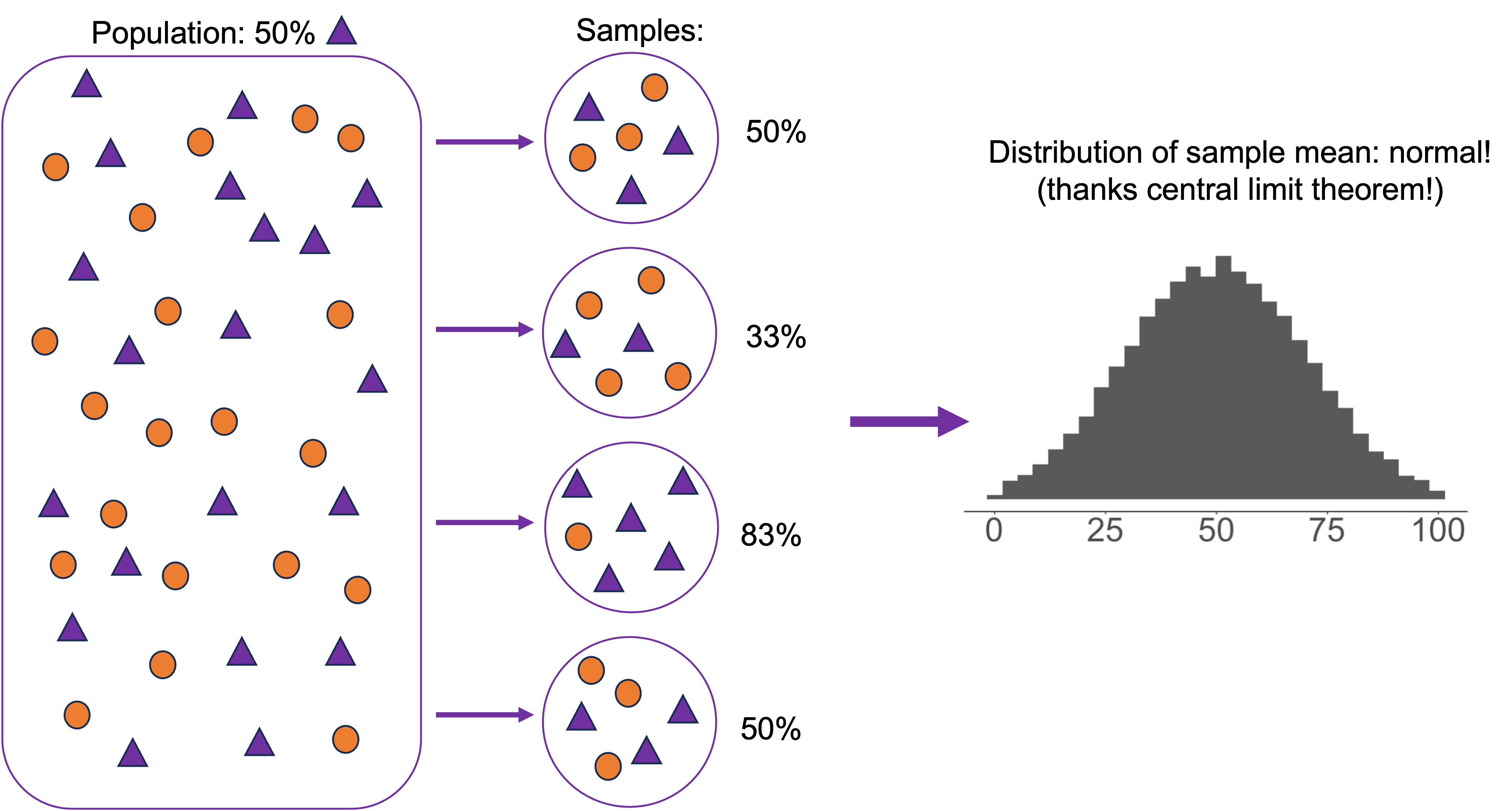
Population parameters and sample statistics
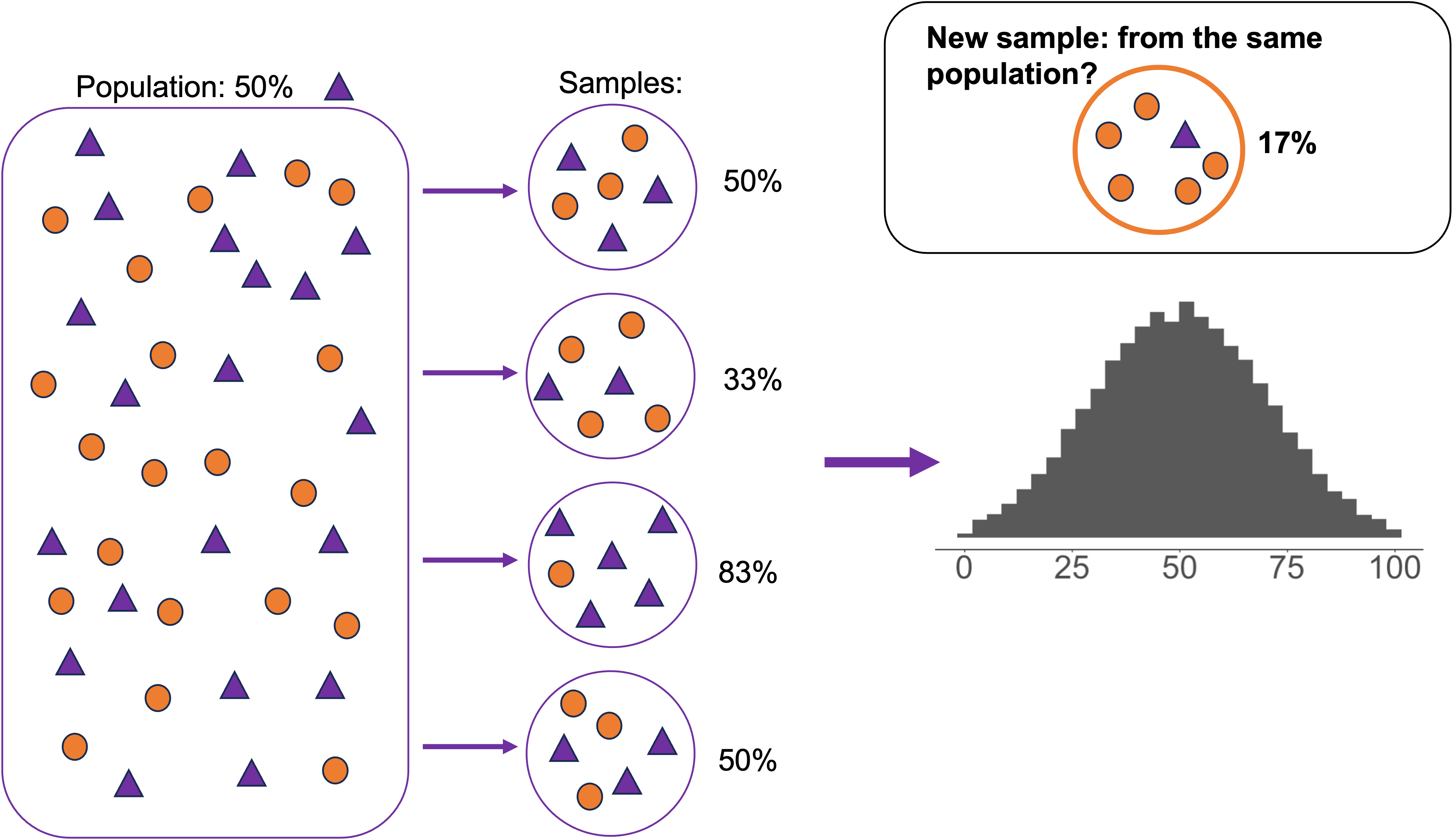
Population parameters and sample statistics: bigger sample size
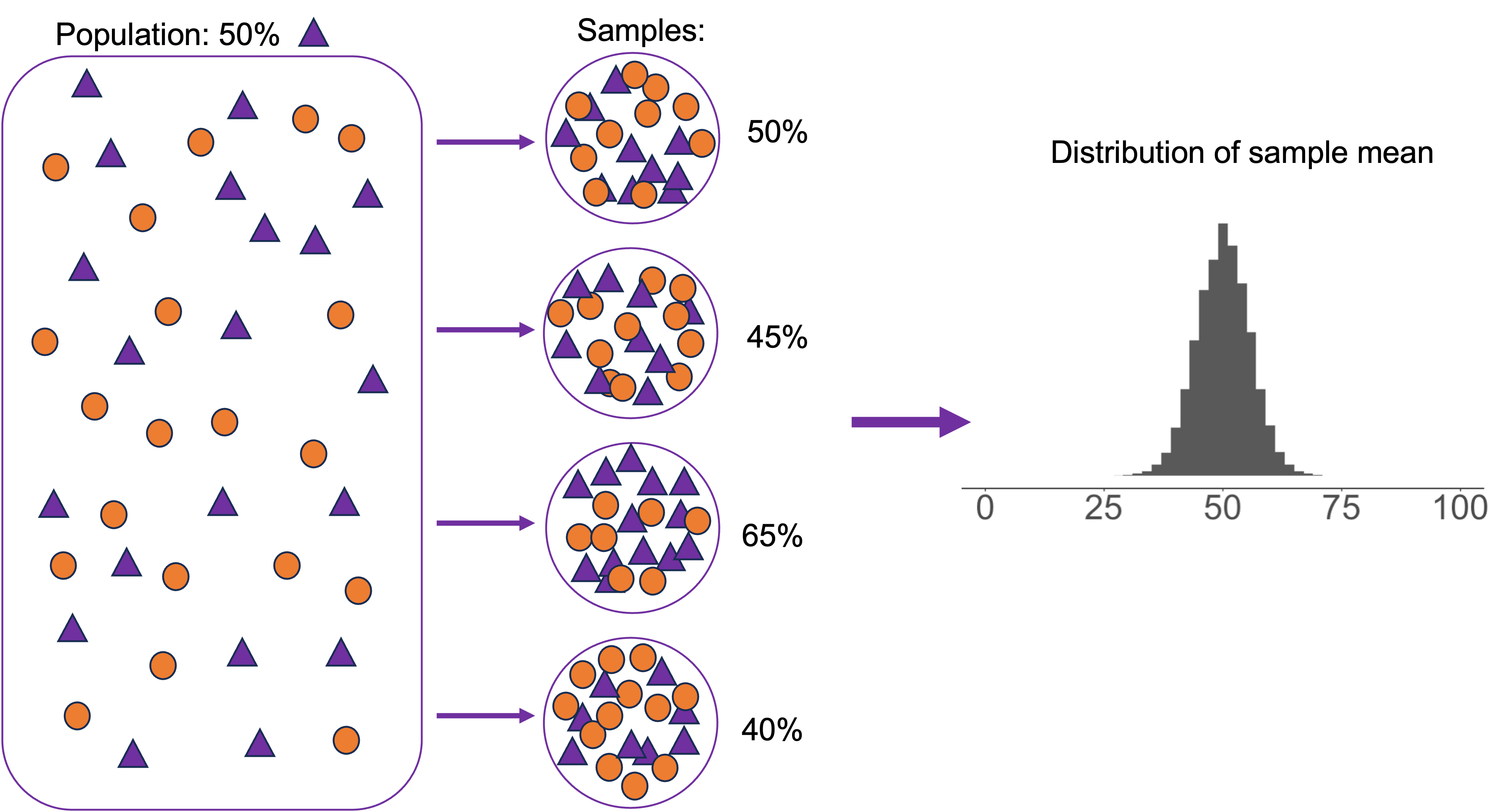
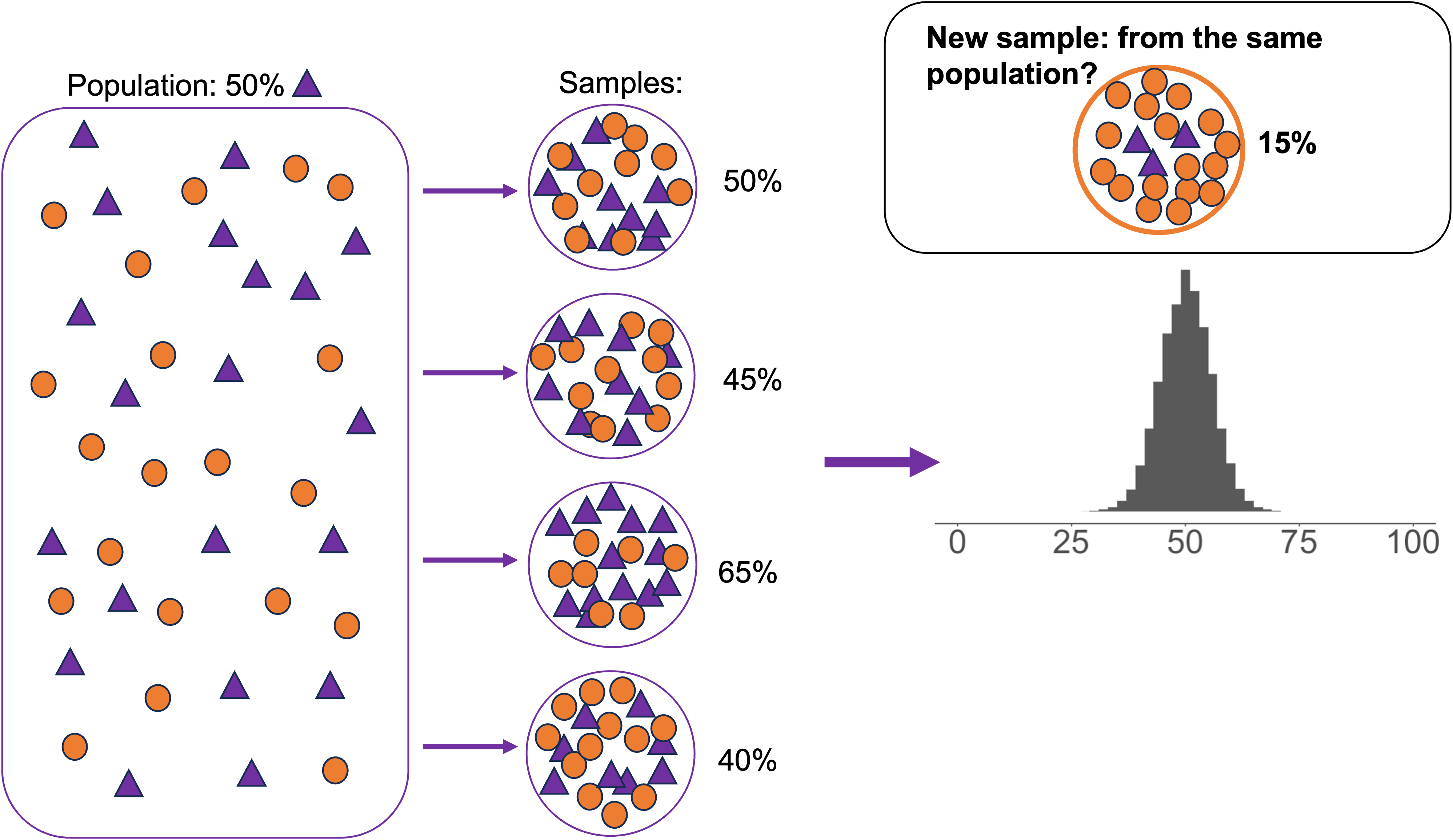
Population parameters and sample statistics: bigger sample size
Normal distribution
- We need to know a little more about normal distributions before we can use them for hypothesis testing
- Parameters of a normal distribution are its mean (center) and standard deviation (spread). Normal distributions are always symmetrical and bell-shaped.

Normal distribution

Z scores example
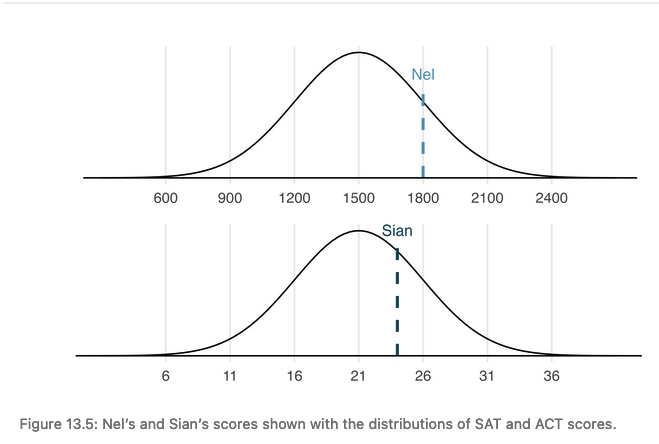
The SAT and ACT follow nearly normal distributions
- SAT: mean = 1500; standard deviation = 300
- ACT: mean = 21, sd = 5
- Nel scored 1800 on the SAT. Sian scored 24 on the ACT. Who did better?
Plots for your projects
Clarification on three variables:
You want to include three variables in one plot when those variables are all part of one question: ie, how does the relationship between X and Y vary by Z.
Another way you may have written three-variable questions:
- Multiple response variables: How does X affect Y, and also how does X affect Z
- Multiple explanatory variables: How does X affect Y, and also how does Z affect Y
In this case, you’re asking multiple two-variable questions: showing them together in one plot wouldn’t make much sense
For this assignment: One plot is required–pick your favorite sub-question
But making more plots is a snap once you have one–if you want to make plots for all sub-questions, go for it!
Other questions?