far below average below average average above average
no degree 21 81 165 52
degree 4 34 74 54
far above average DK
no degree 2 5
degree 8 0Hypothesis tests pt 4
Lecture 16
2023-06-14
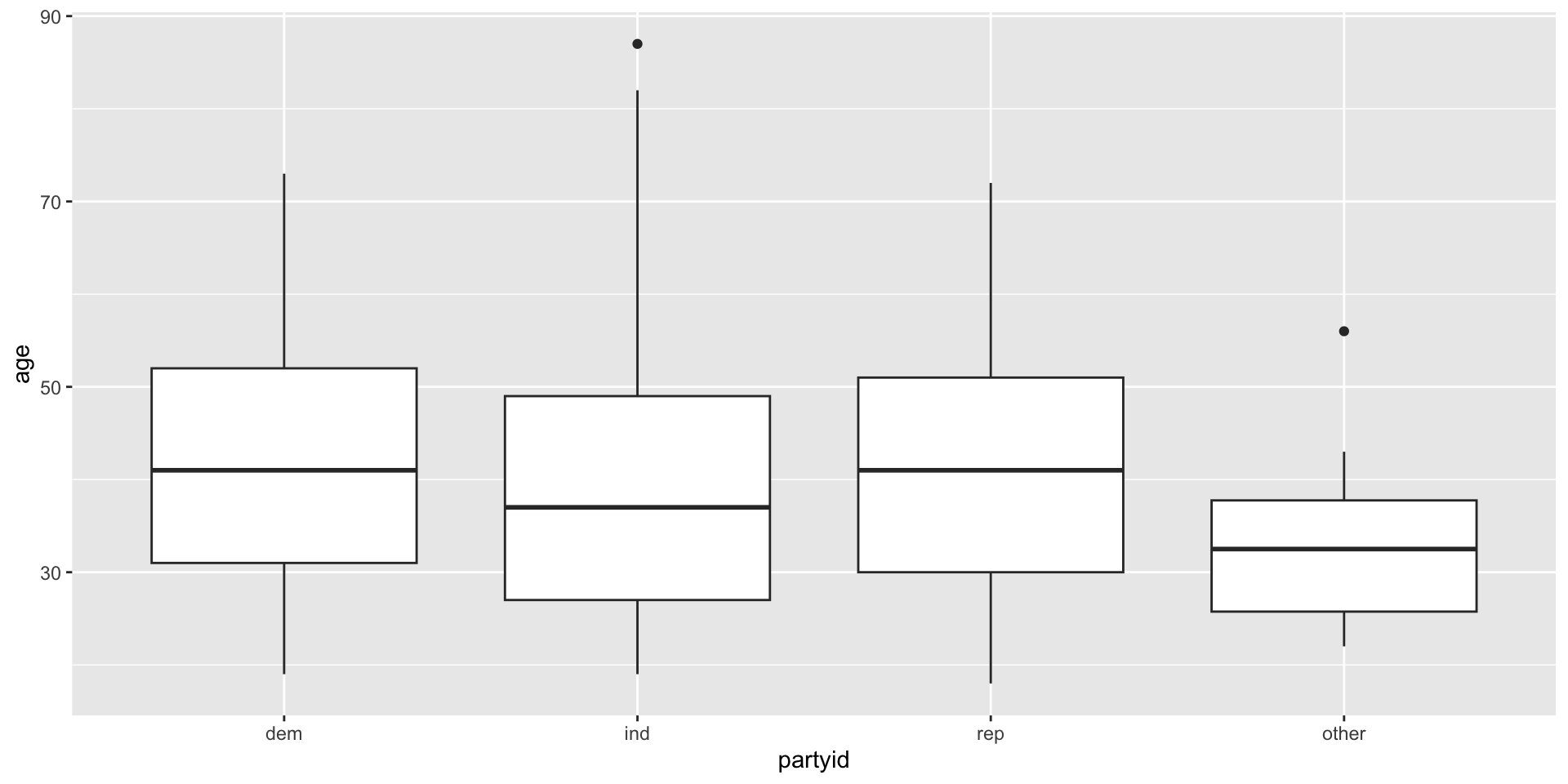
Bar charts for two categorical vars
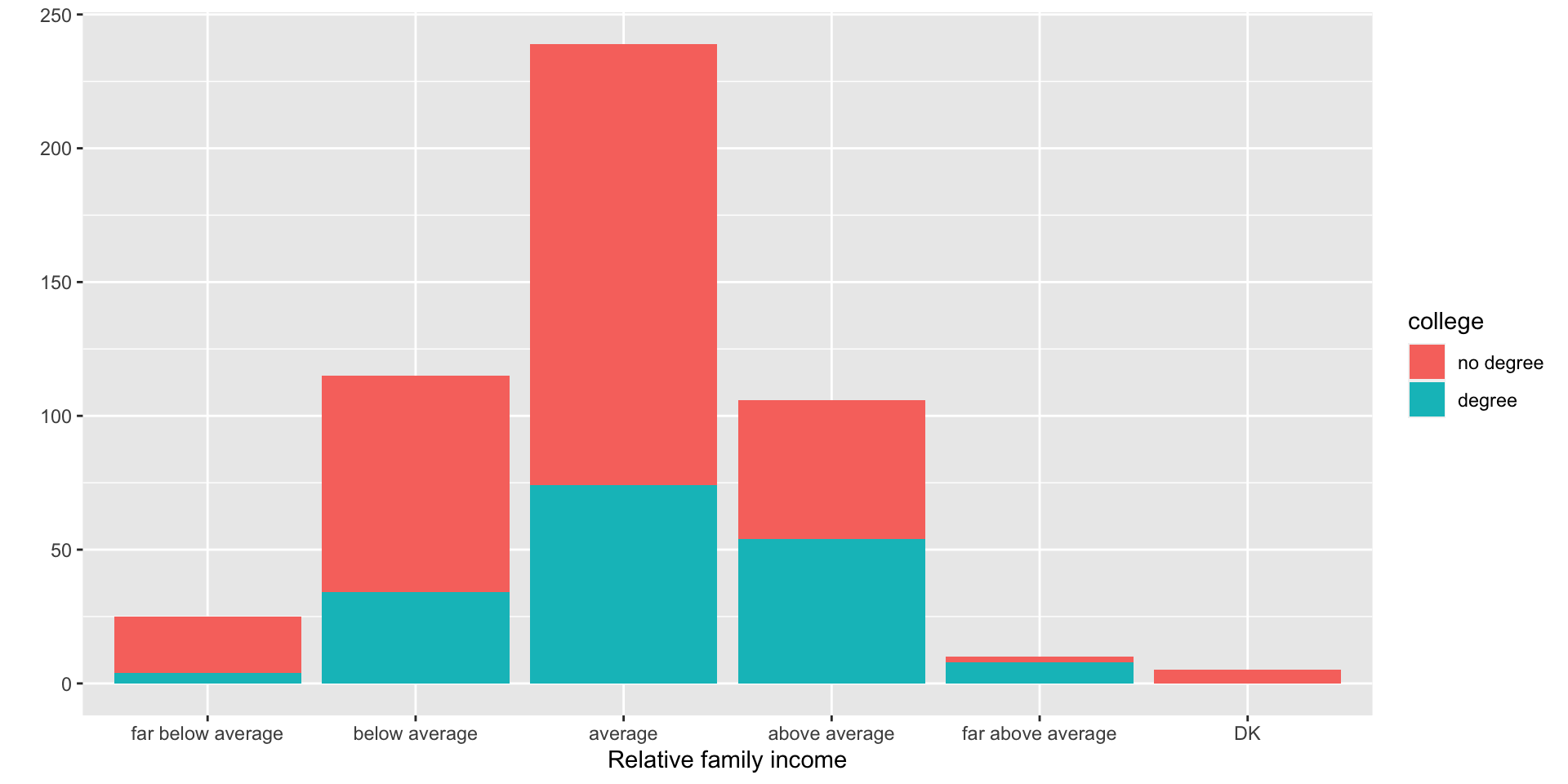
- Example: How is the probability of obtaining a college degree related to self-identified income category?
- Stacked bar chart: Good at showing the overall distribution. We can see that most people think their income is average.
Bar charts for two categorical vars
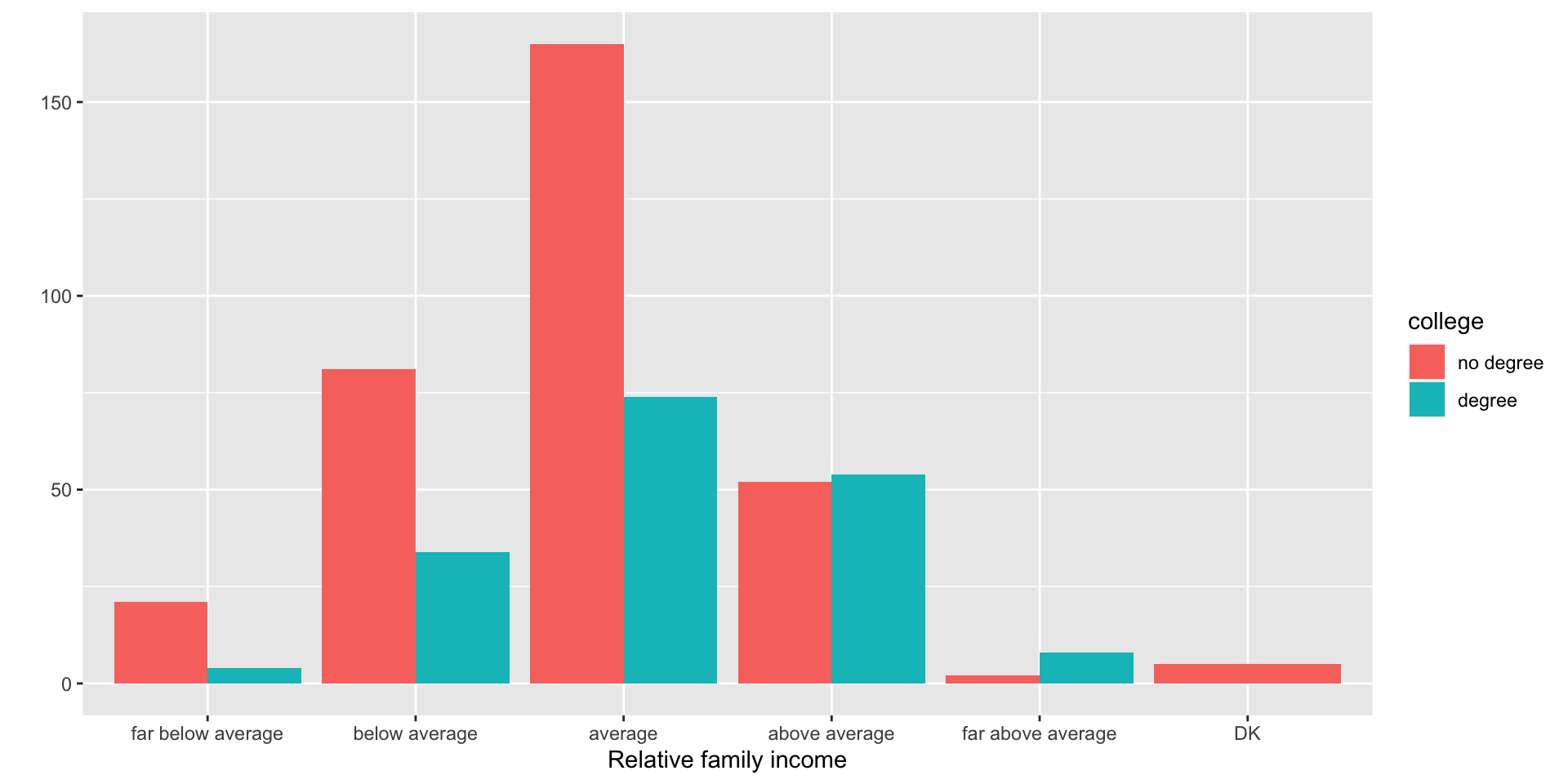
- Example: How is the probability of obtaining a college degree related to self-identified income category?
- Dodged bar chart: Good at showing the distributions of the two groups next to each other. Now we can see that there are fewer people with degrees.
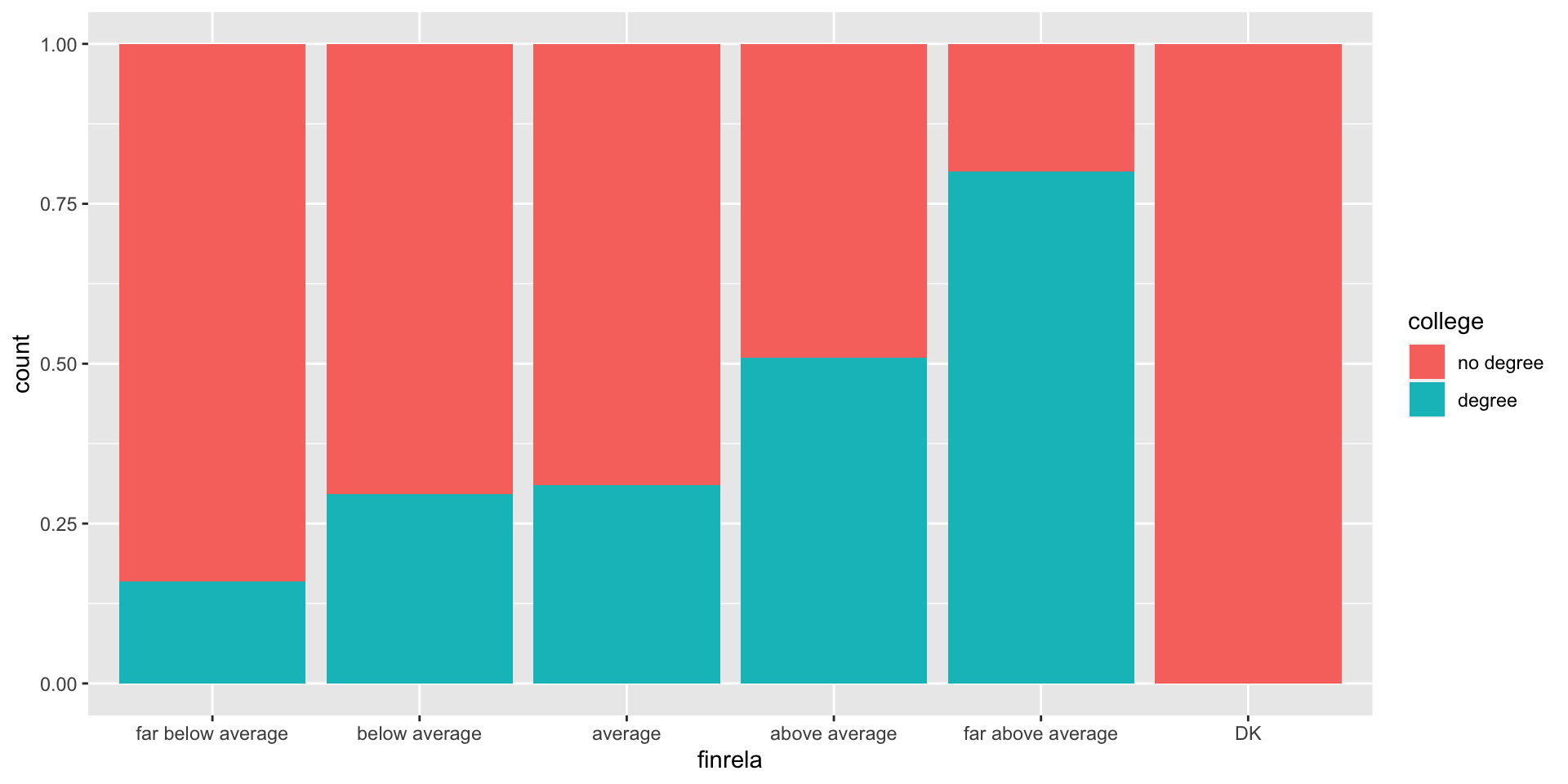
Bar charts for two categorical vars
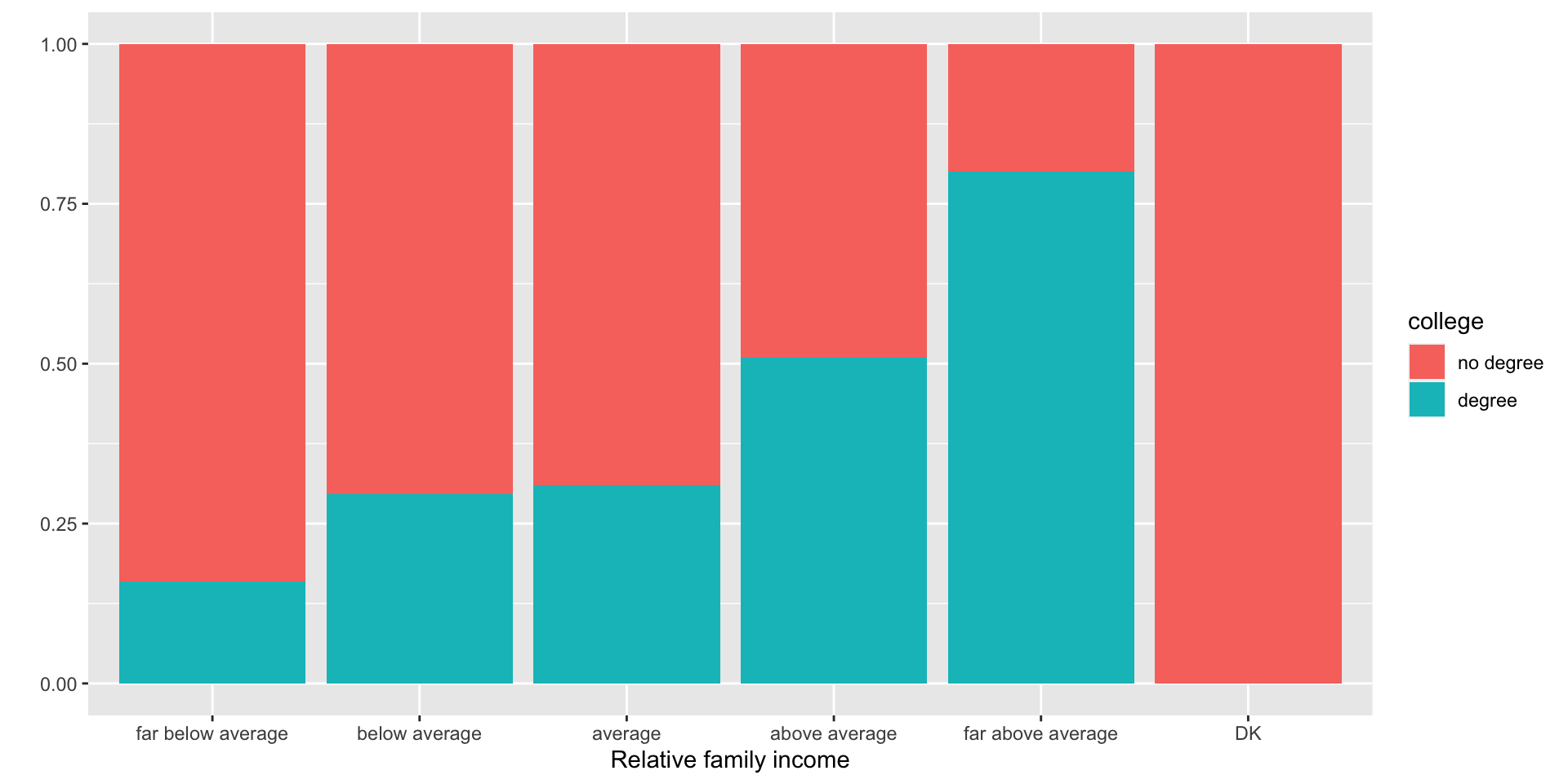
- Example: How is the probability of obtaining a college degree related to self-identified income category?
- Proportion bar chart: Good at comparing the compositions of the bars. We lose information on the distribution as a whole, but we gain information on whether people from both groups are evenly distributed between income classes.
There are many types of tests
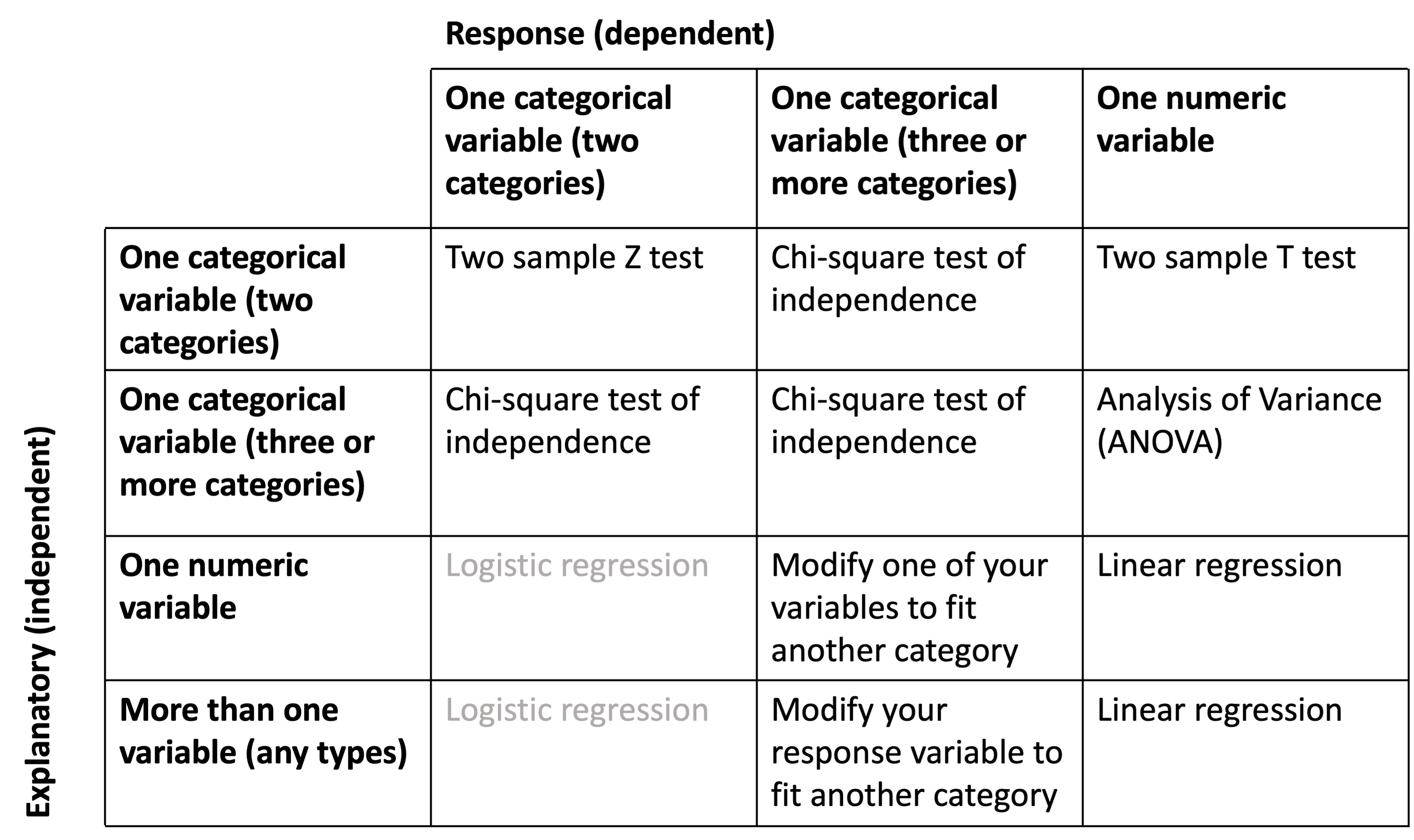
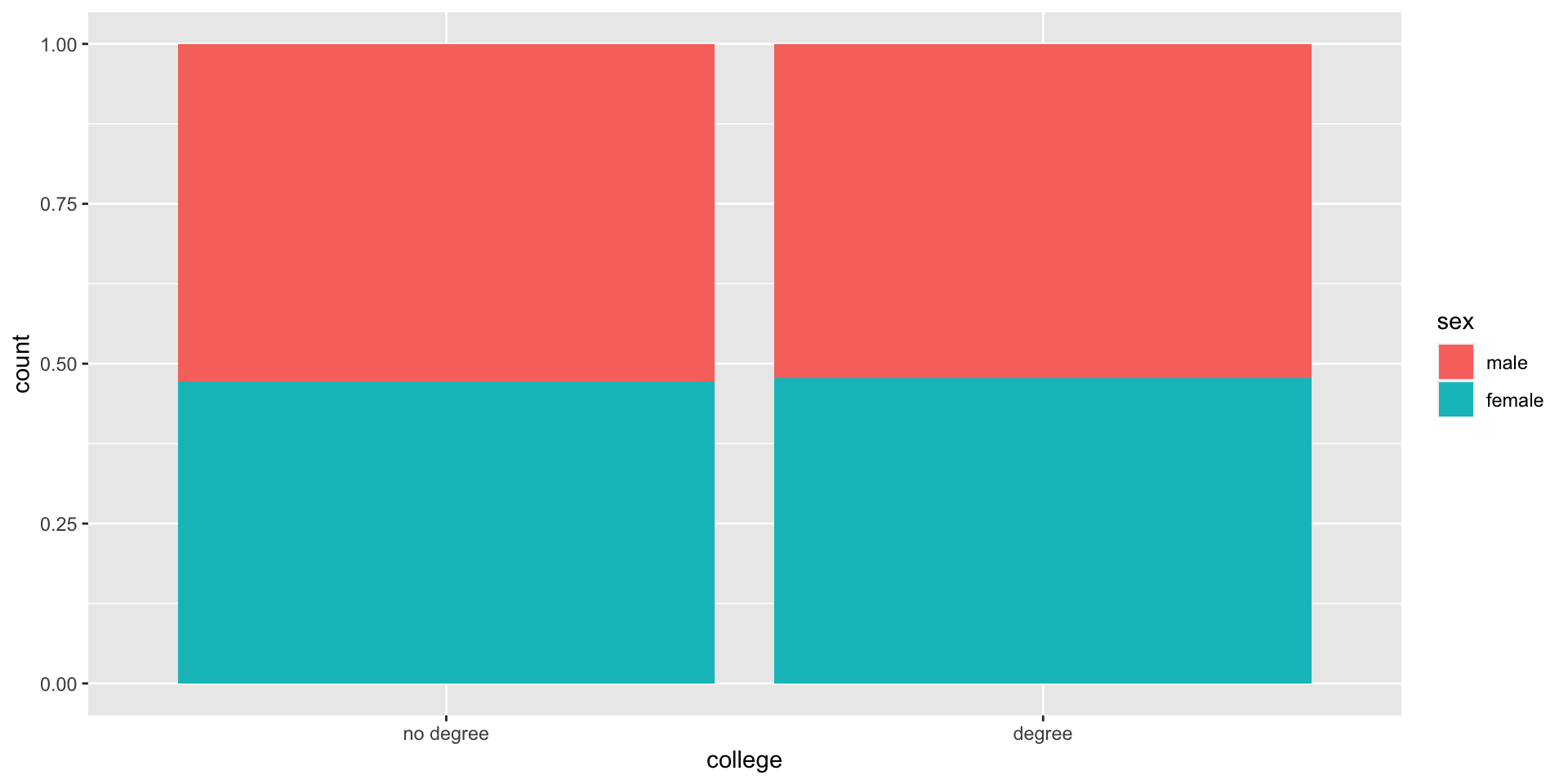
Two sample Z test
- Explanatory: categorical with two categories
- Response: categorical with two categories
- Testing for: Difference in group proportions!
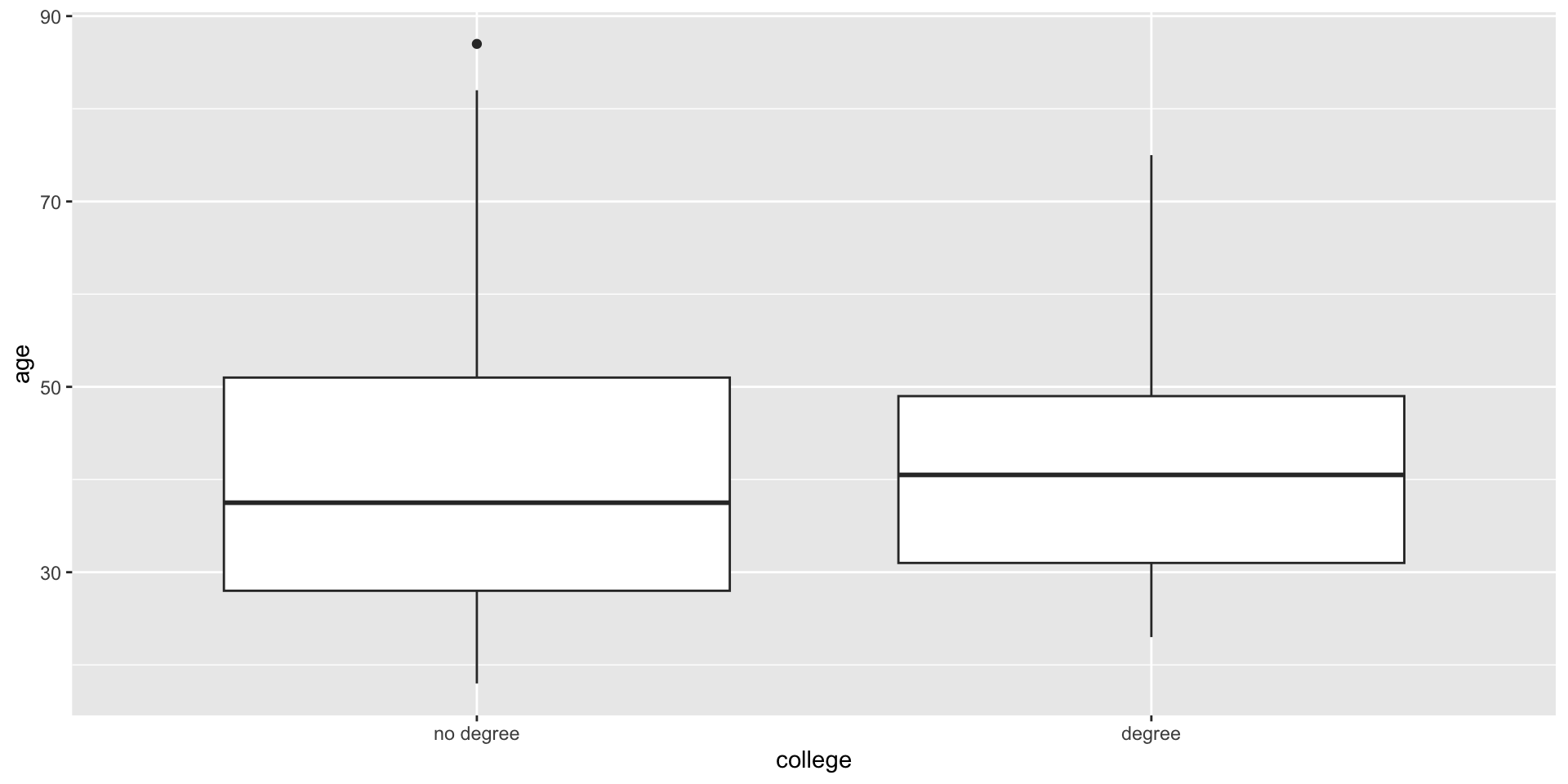
Two sample T test
- Explanatory: categorical with two categories
- Response: numeric
- Testing for: Difference in group means!
Chi square test of independence
- Explanatory: categorical with any number of categories
- Response: categorical with any number of categories
- Testing for: Patterns in how observations are distributed between groups!
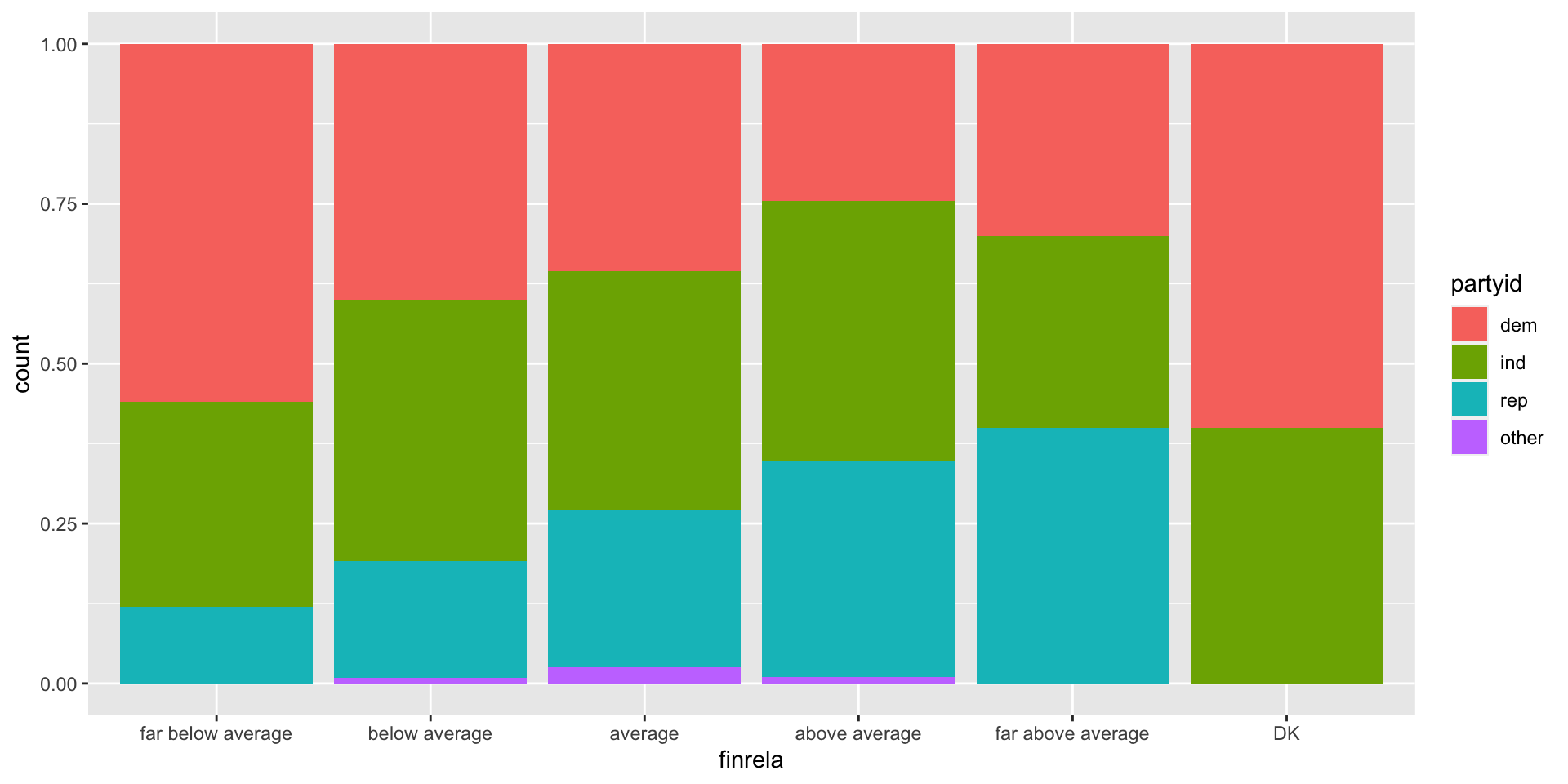
Chi square test of independence
- Explanatory: categorical with any number of categories
- Response: categorical with any number of categories
- Testing for: Patterns in how observations are distributed between groups!
Analysis of Variance (ANOVA)
- Explanatory: categorical with three or more categories
- Response: numeric
- Testing for: Differences in means between more groups!
Linear regression
- Explanatory: numeric or multiple variables
- Response: numeric
- Testing for: Non-zero slopes!

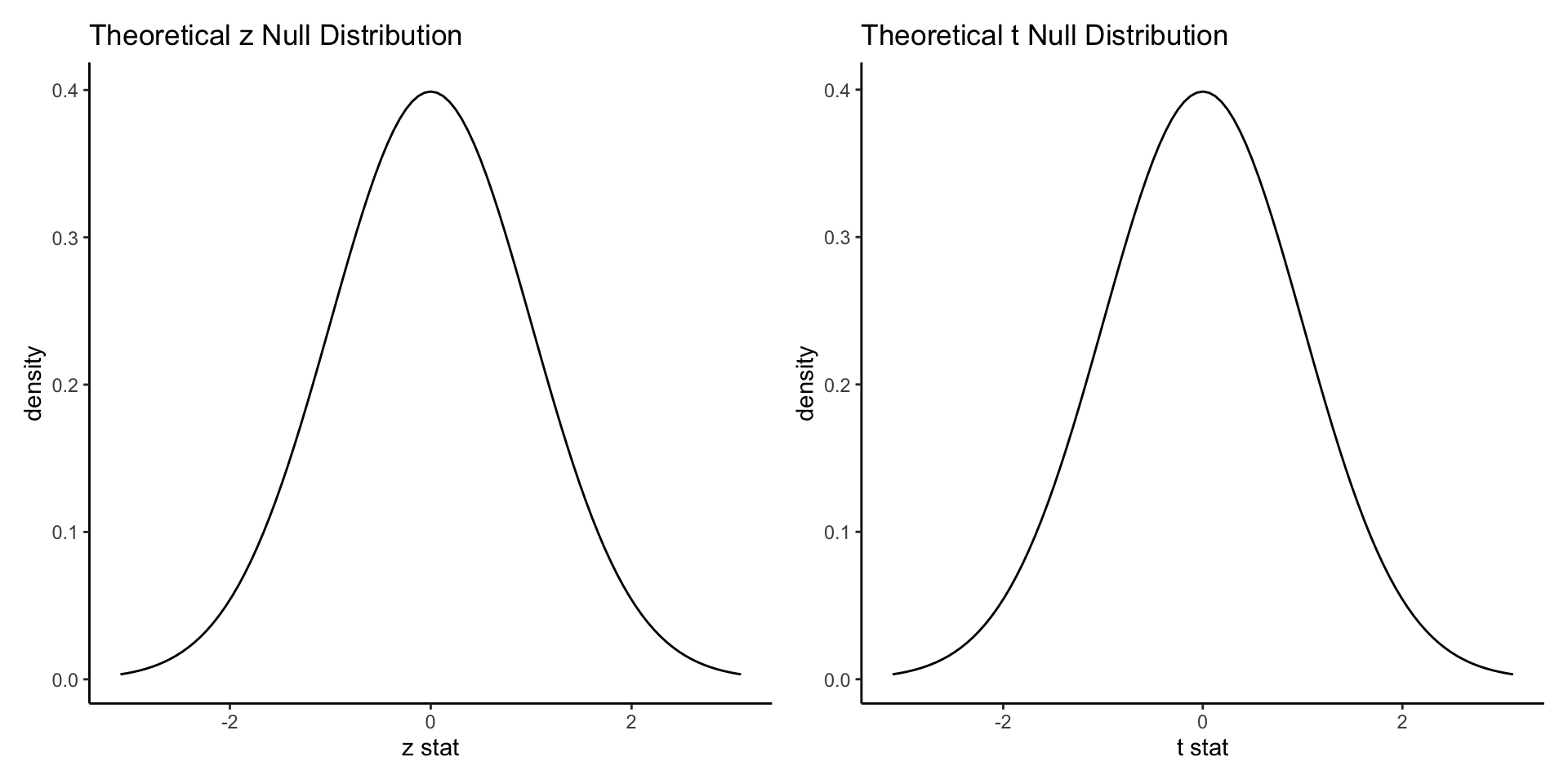
Normal and nearly normal distributions
- Normal: Two sample Z test, linear regression slope test
- Nearly normal (t distribution): Two sample T test
- Symmetrical; centered at 0; bell-shaped
- Either one-tailed or two-tailed tests make sense
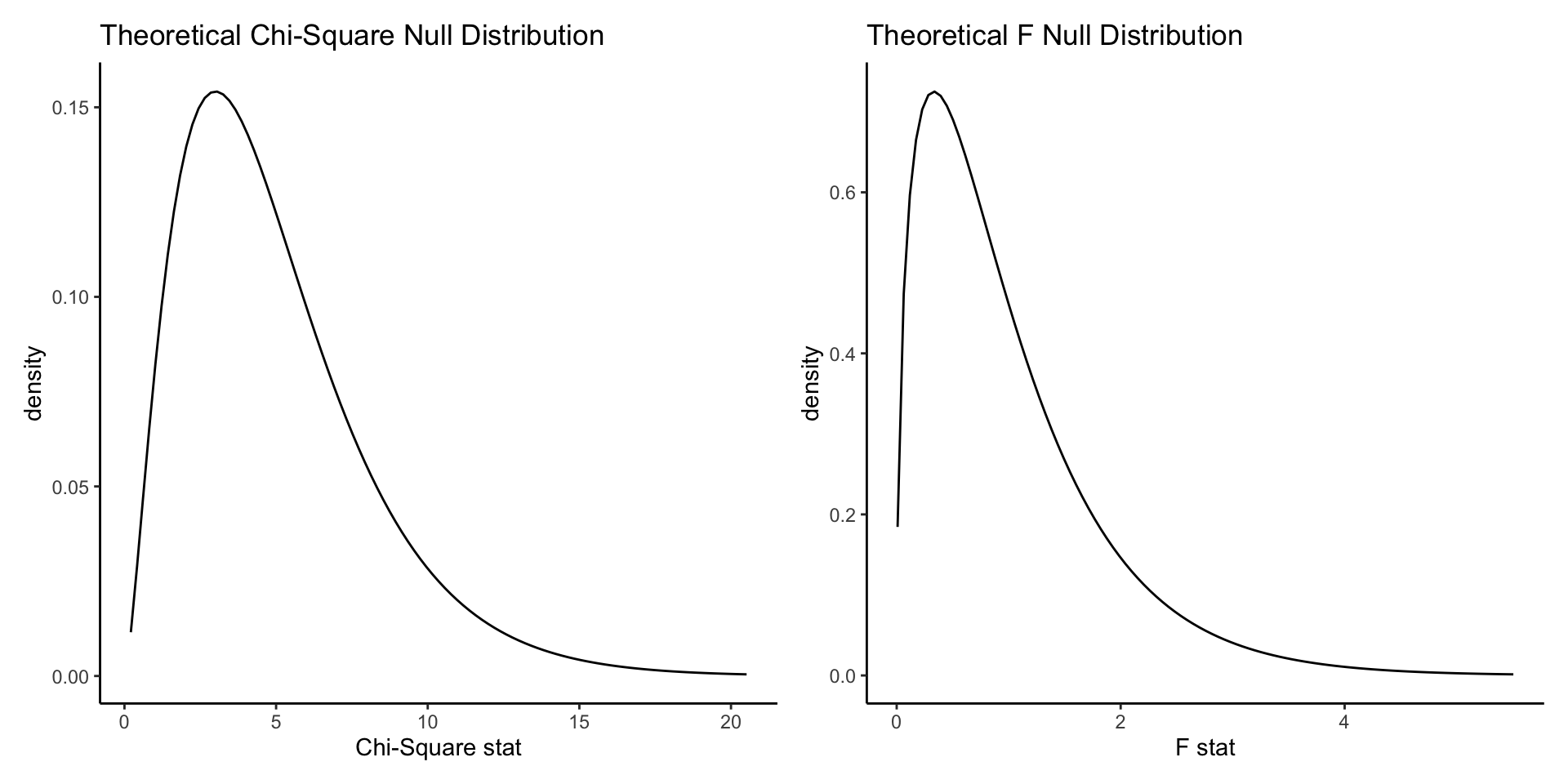
Asymmetrical distributions
- Chi-square test: chi square distribution
- Analysis of Variance (ANOVA): F distribution
- These values can be thought of as distances
- Strictly positive; asymmetrical and long-tailed
- “More extreme” means further away—ie, more positive. So all tests are one-tailed.
Example

Chi square example
- Correct test: Chi square

Chi square example
- Do we reject or fail to reject our null hypothesis?
- What can we conclude about our research question?
# 4. Visualize it!
visualize(null_dist) +
shade_p_value(obs_stat = test_stat,
direction = "greater")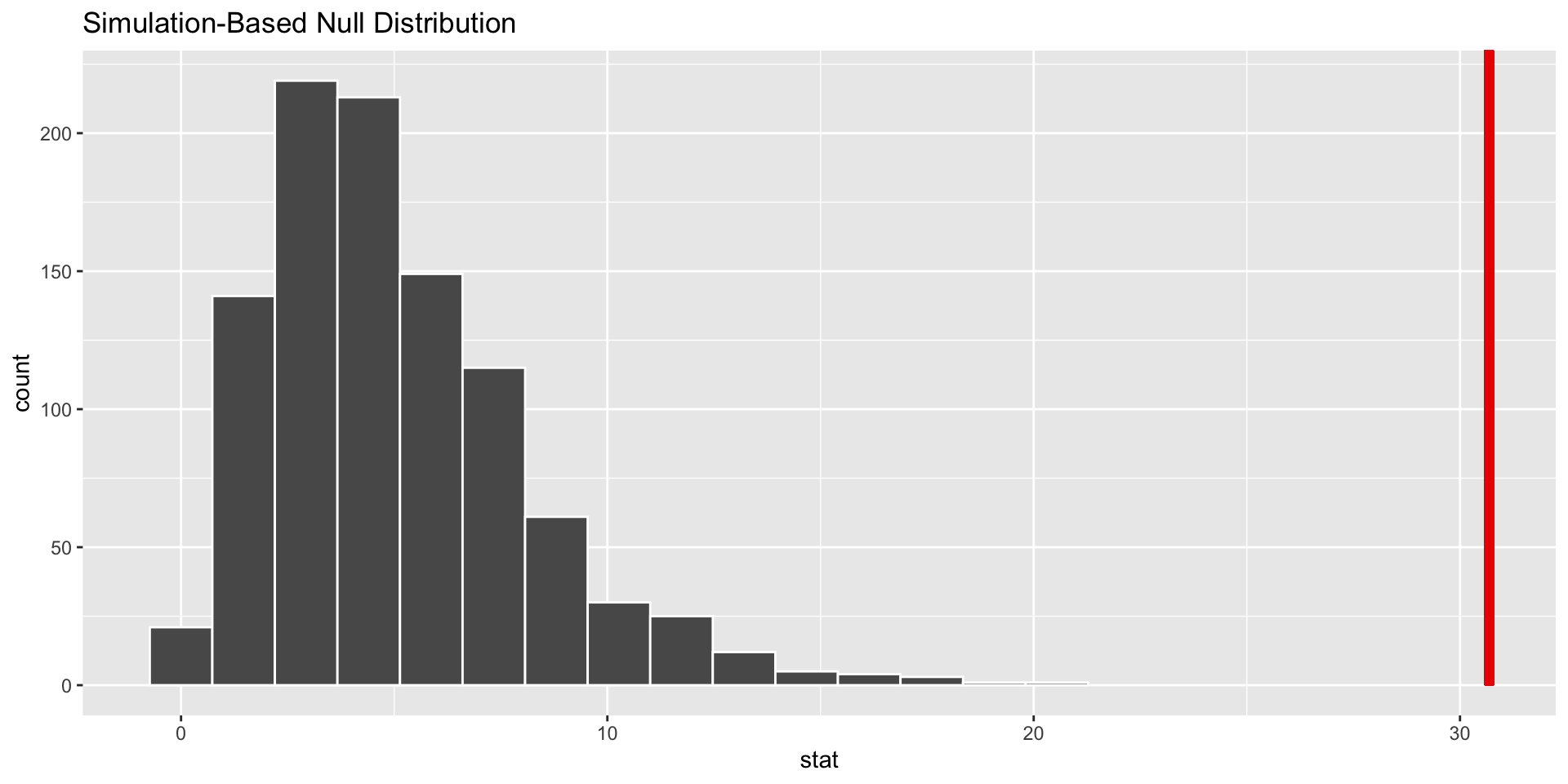
![]()